"Binaural Codebook-based Speech Enhancement with Atomic Speech Presence Probability"
Sean Wood, Johannes Stahl, Pejman Mowlaee
- Audio samples -
Below, we present some audio samples demonstrating the impact of the proposed binaural speech enhancement approach based on atomic speech presence probability (ASPP). The benchmark methods are the Model-based EM Source Separation and Localization (MESSL) [1] and RANdom SAmple Consensus (RANSAC) [2].
[1] M. I. Mandel, R. J. Weiss, and D. P. Ellis, “Model-based expectationmaximization source separation and localization,” IEEE Transactions on Audio, Speech and Language Processing, vol. 18, no. 2, pp. 382–394, 2010.
[2] J. Traa and P. Smaragdis, “Multichannel source separation and tracking with RANSAC and directional statistics,” IEEE/ACM Transactions on Audio Speech and Language Processing, vol. 22, no. 12, pp. 2233–2243, 2014.
Female speech (dr6_msds0_si1707) in Ventilation noise at SNR = 0 (dB):
IPD-ILD-ICM weighting factors: [0.1508,0.1902,0.6591]sigma=2.2361,kappa=3.1623,alpha=31.6228,beta=1
Clean
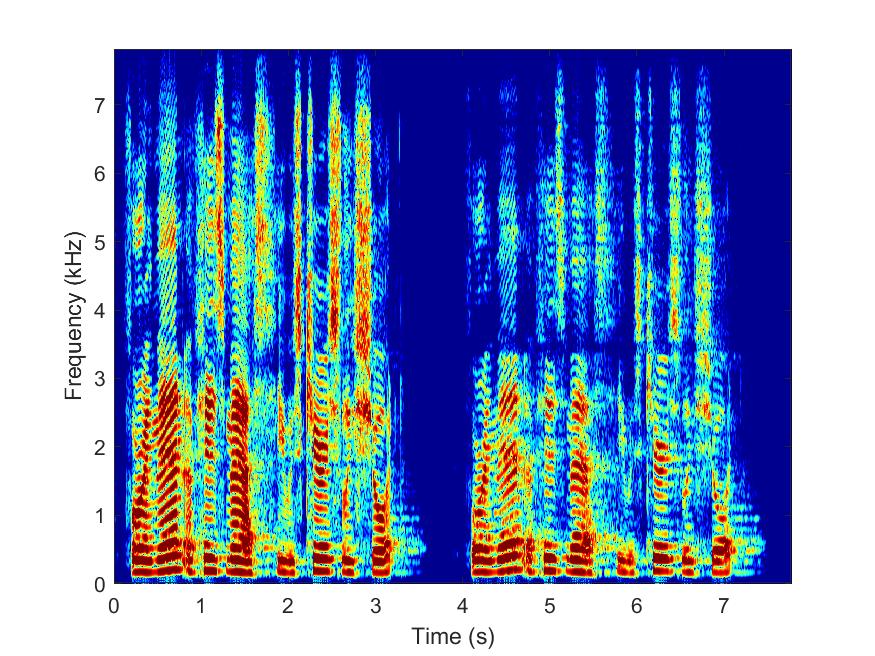
|
Noisy
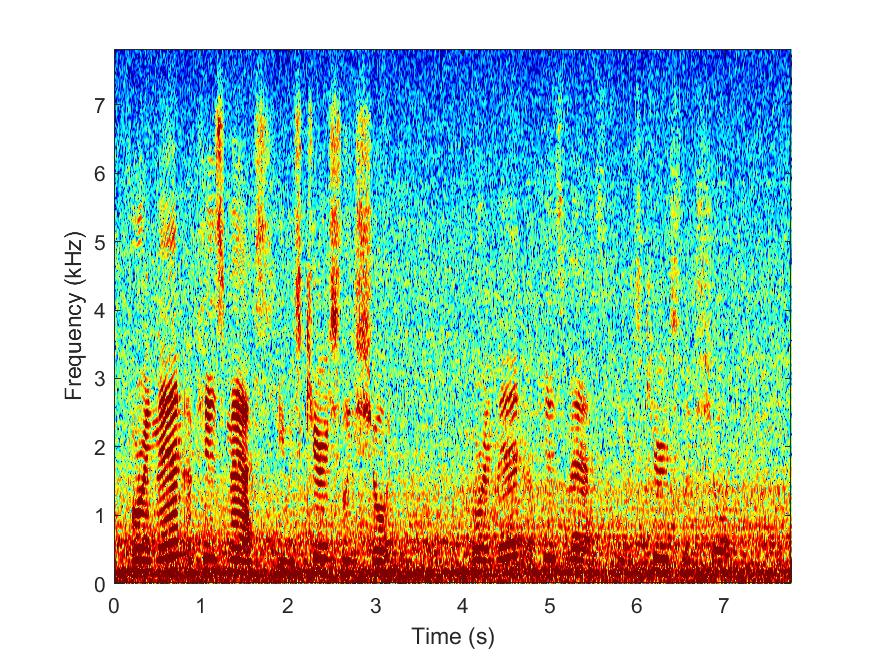 --> -->
|
Proposed
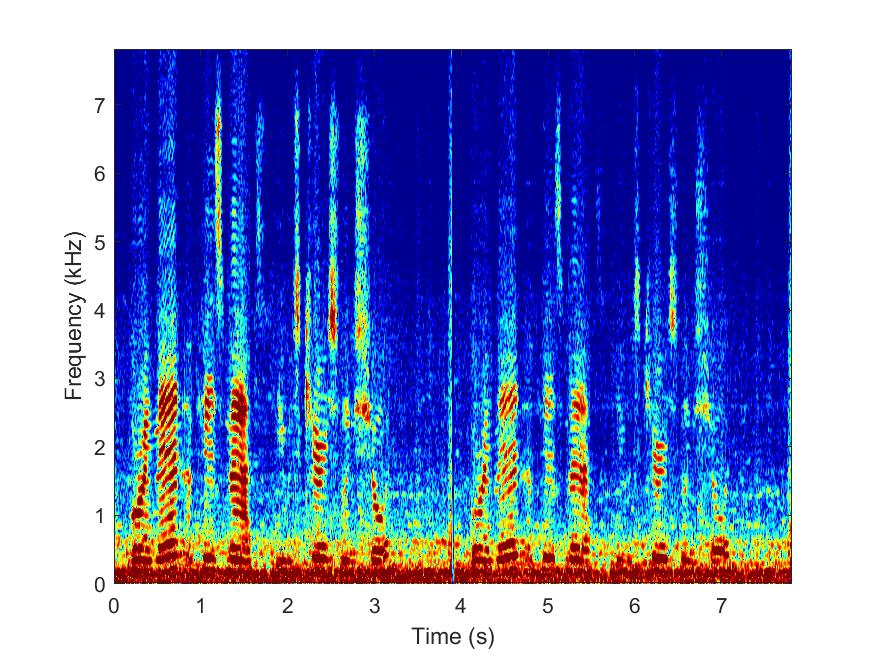 --> -->
|
MESSL
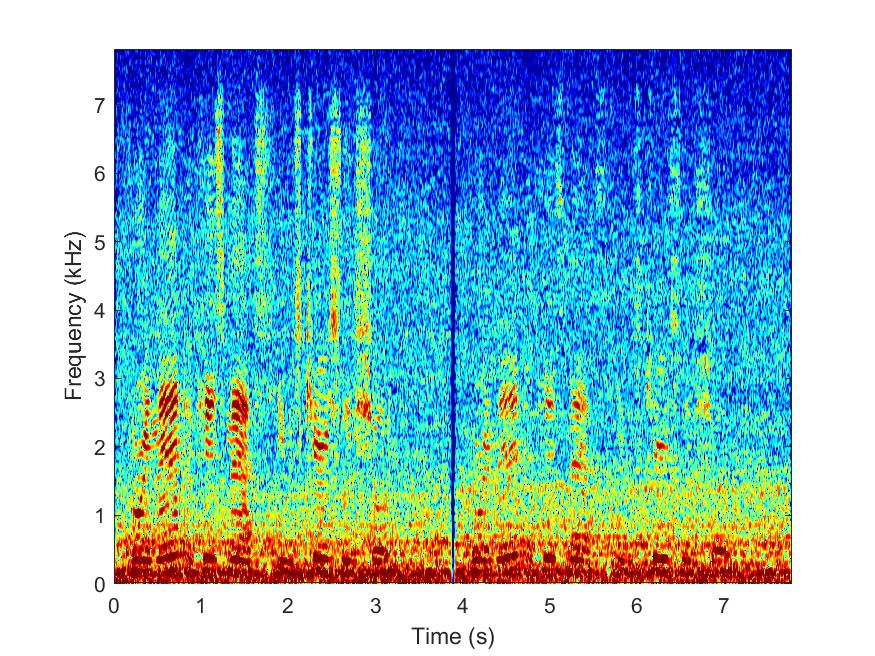 --> -->
|
RANSAC
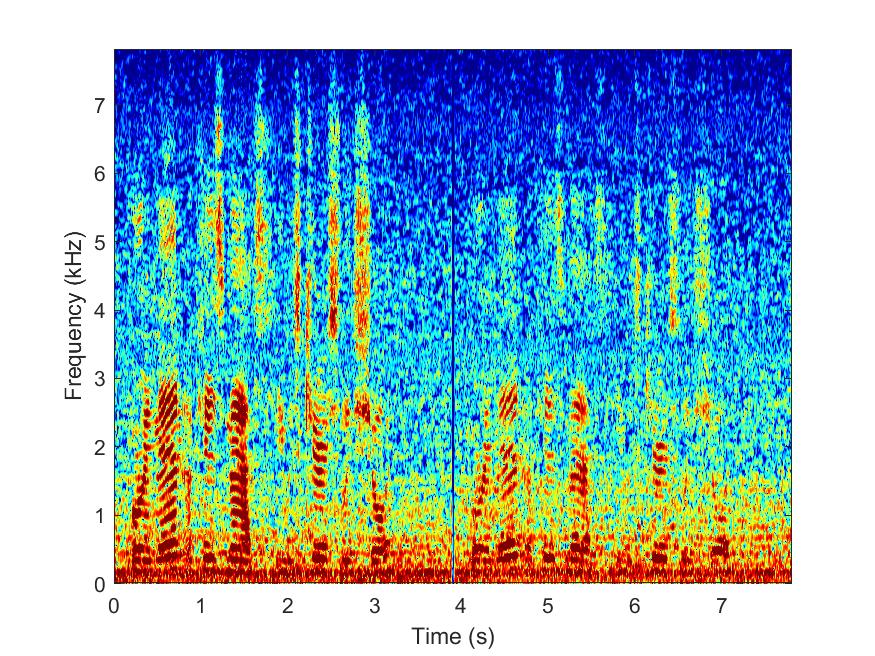 --> -->
|
Female speech (dr7_fjsk0_si1682) in babble noise at SNR = 0 (dB):
IPD-ILD-ICM weighting factors: [0.2960,0.3317,0.3723]
sigma=2.2361,kappa=3.1623,alpha=31.6228,beta=1
Clean
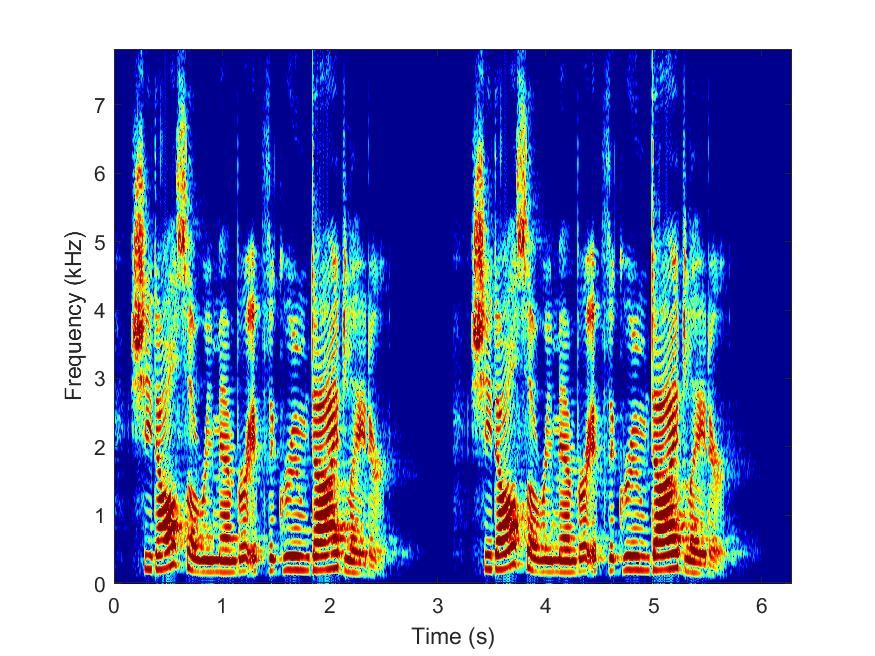 --> -->
|
Noisy
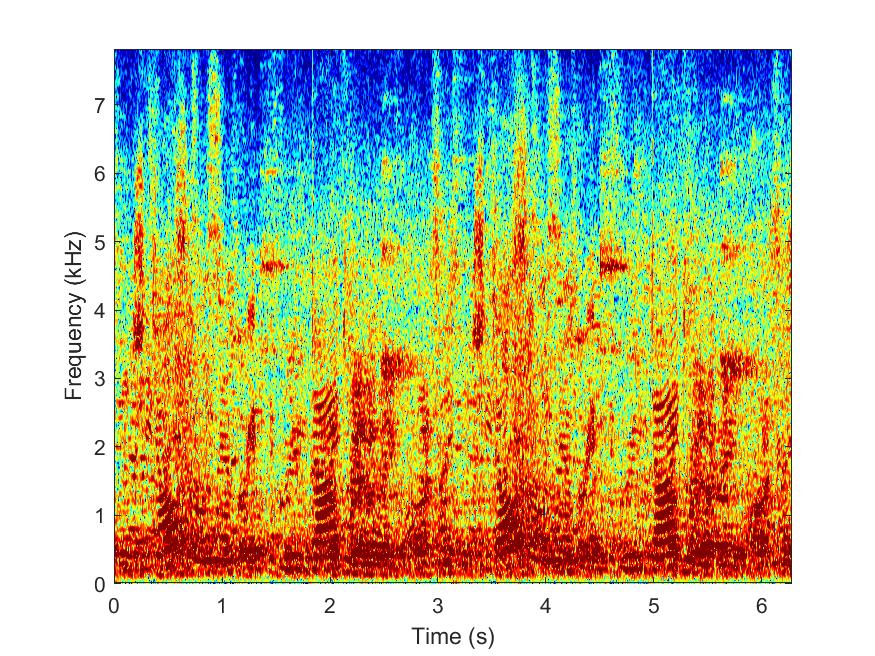 --> -->
|
Proposed
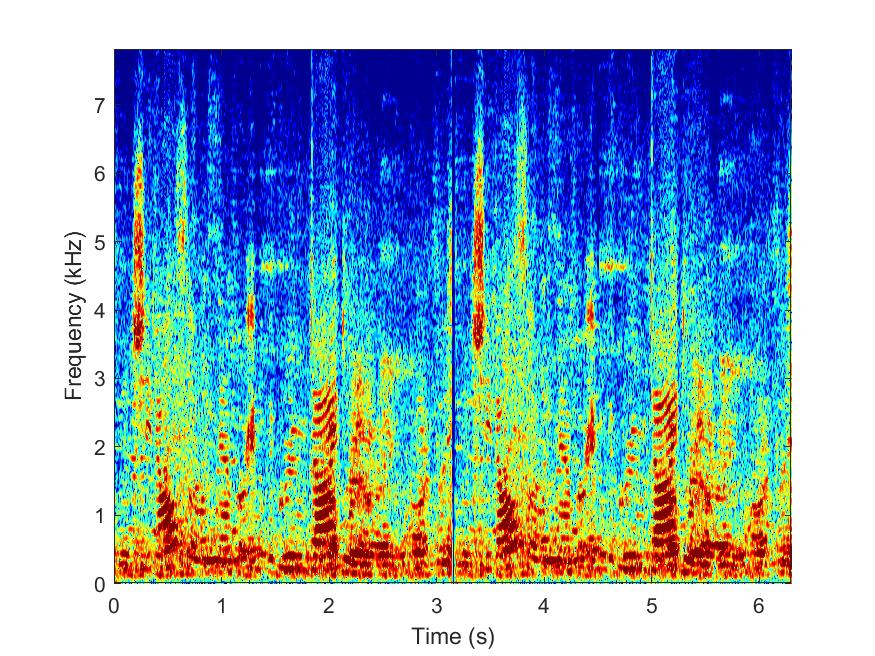 --> -->
|
MESSL
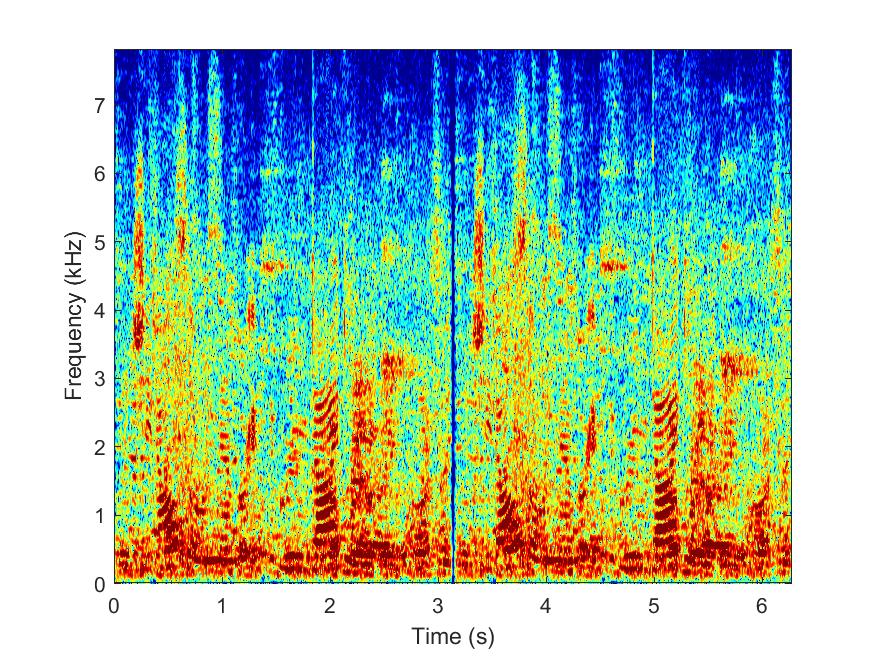 --> -->
|
RANSAC
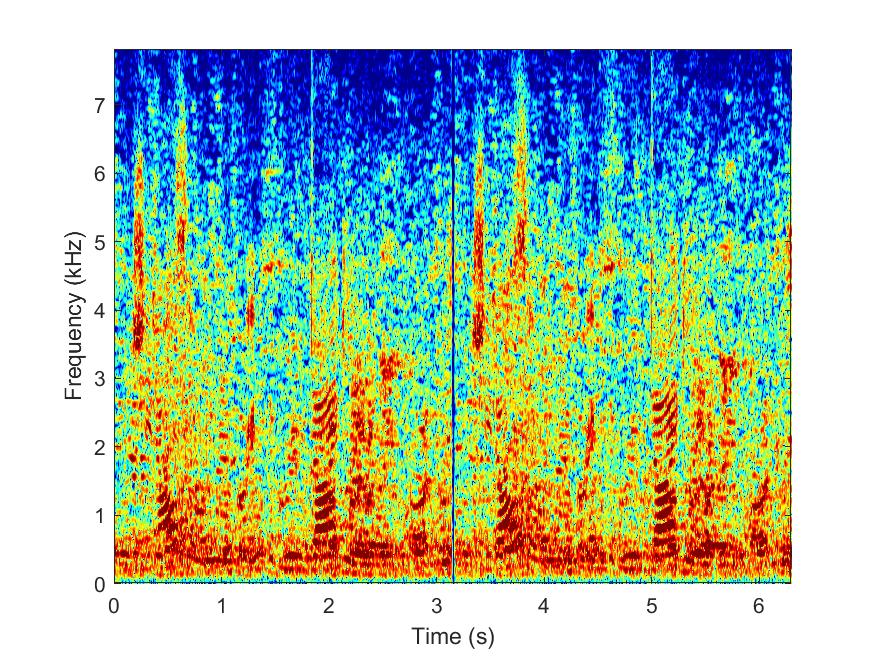 --> -->
|
Clean
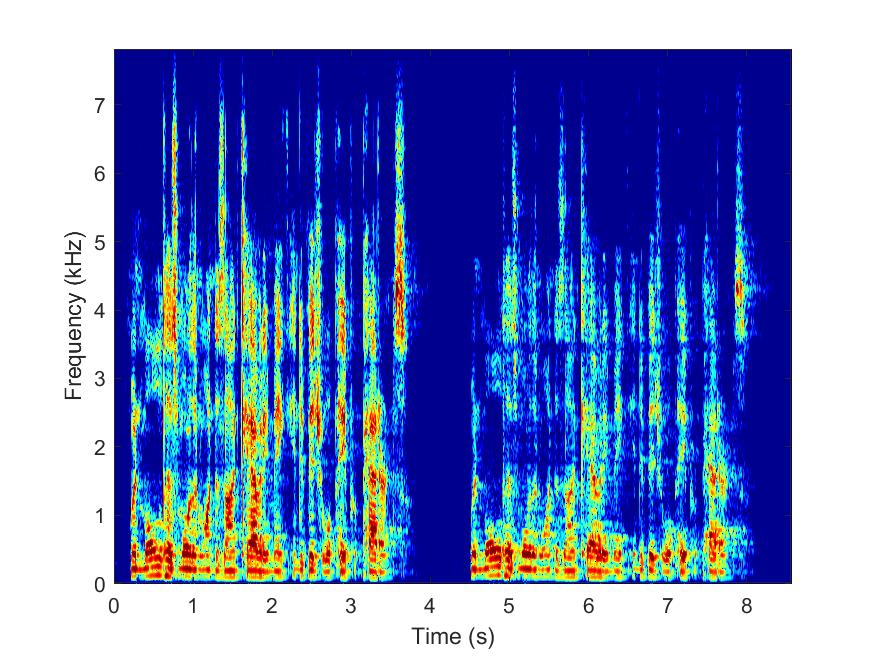 --> -->
|
Noisy
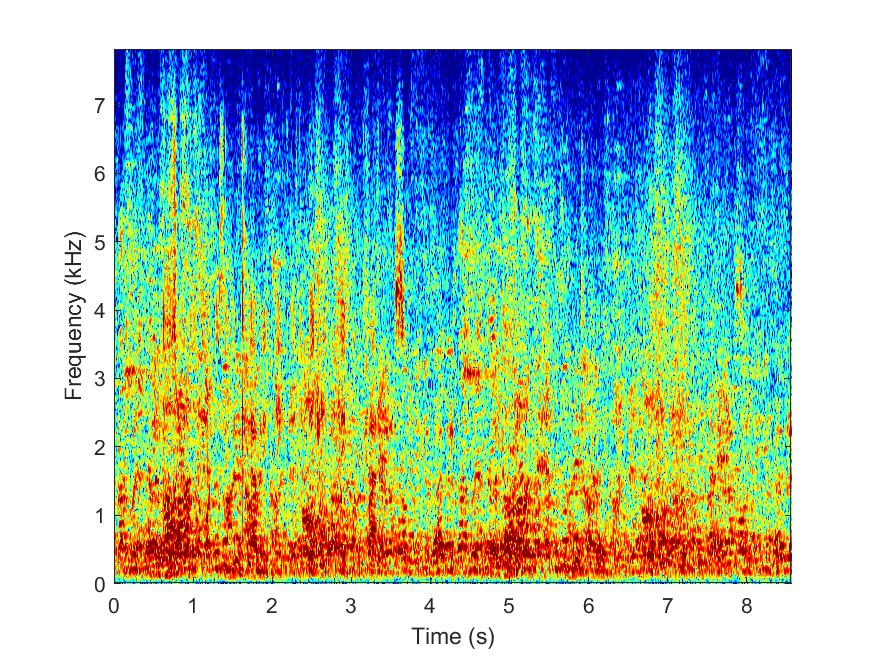 --> -->
|
Proposed
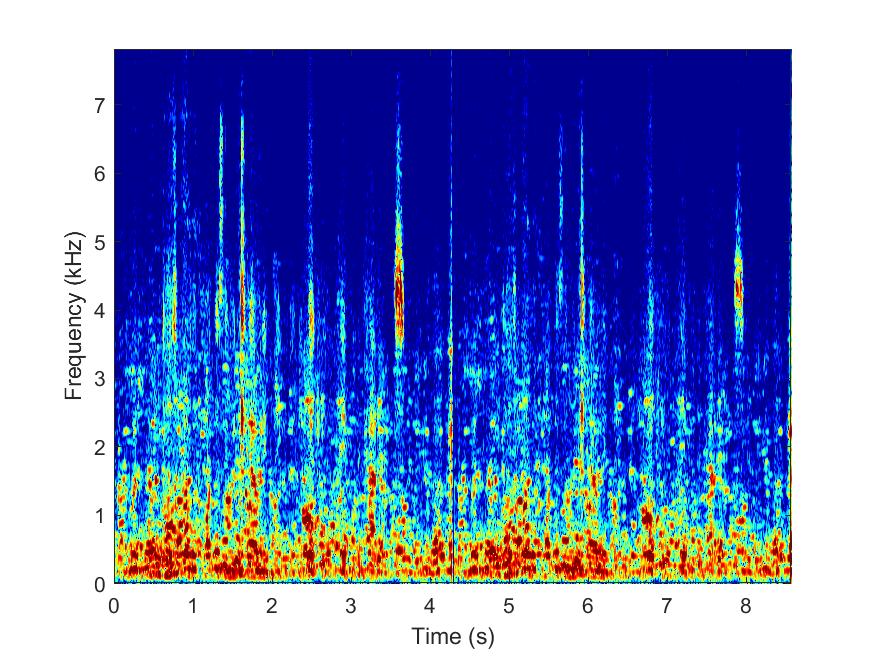 --> -->
|
MESSL
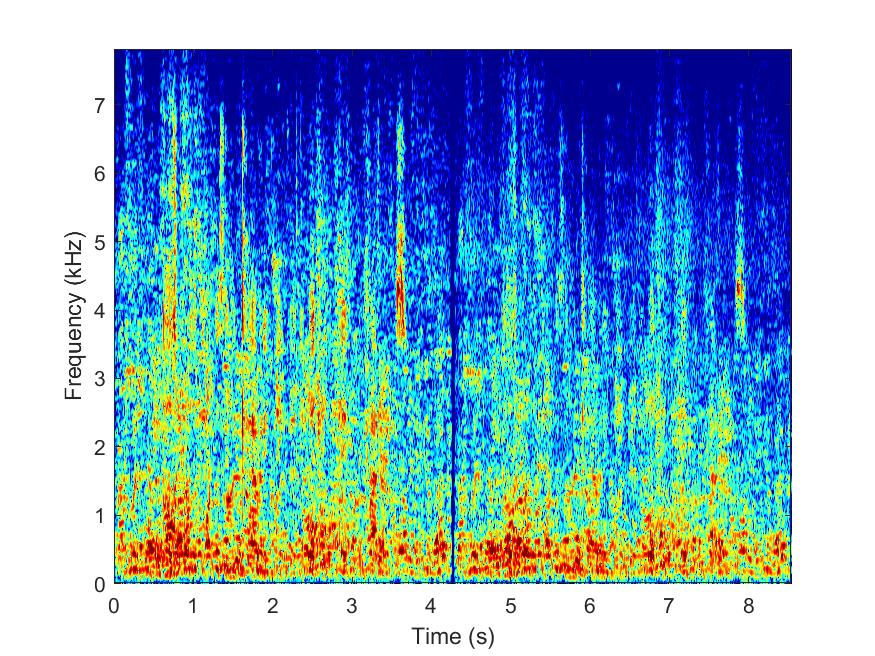 --> -->
|
RANSAC
 --> -->
|
Clean
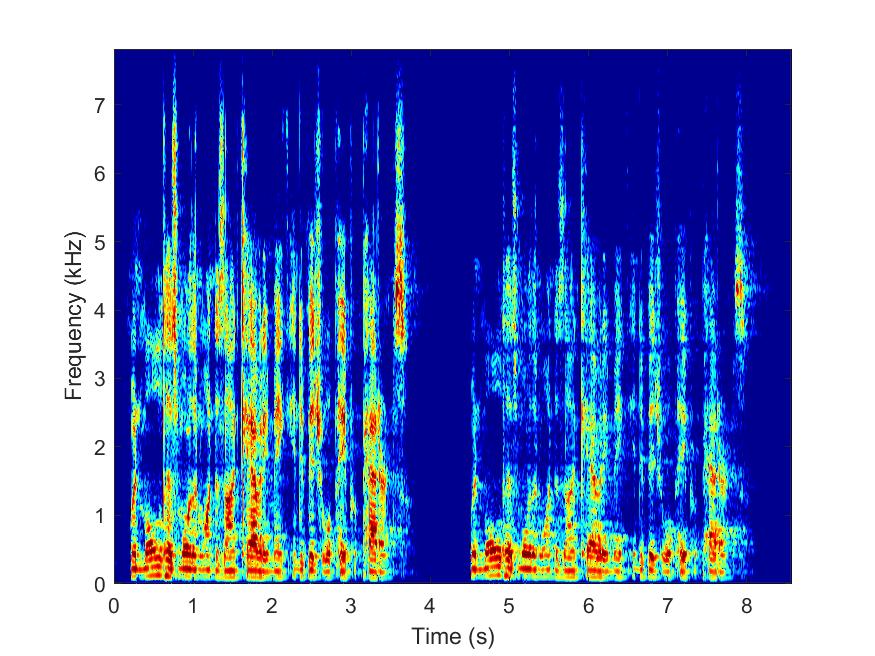 --> -->
|
Noisy
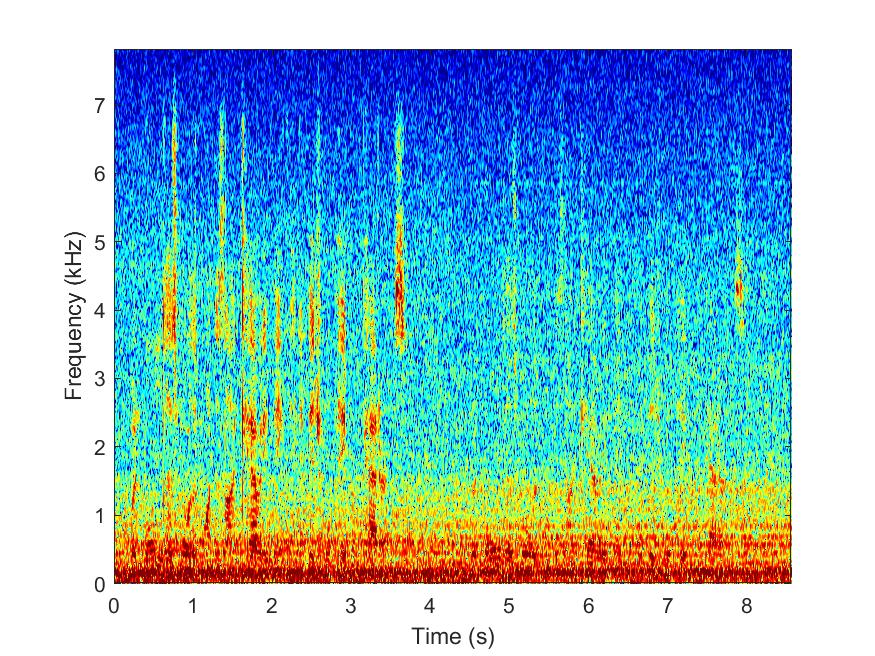 --> -->
|
Proposed
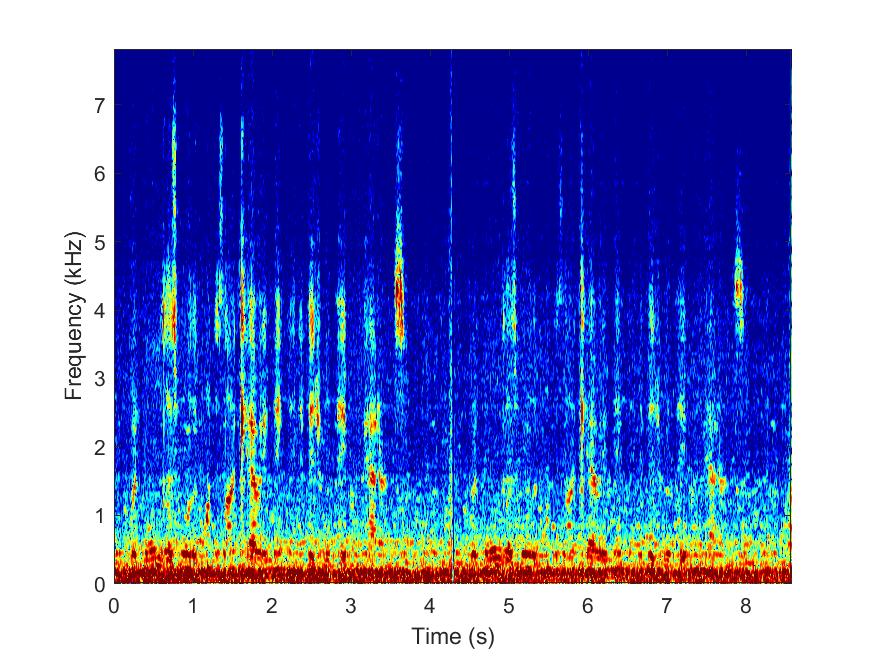 --> -->
|
MESSL
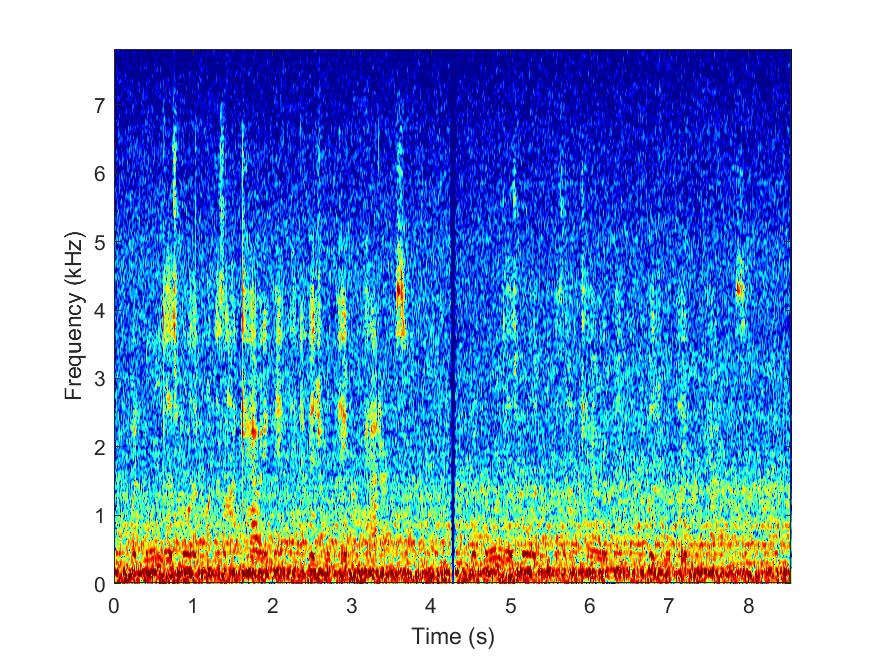 --> -->
|
RANSAC
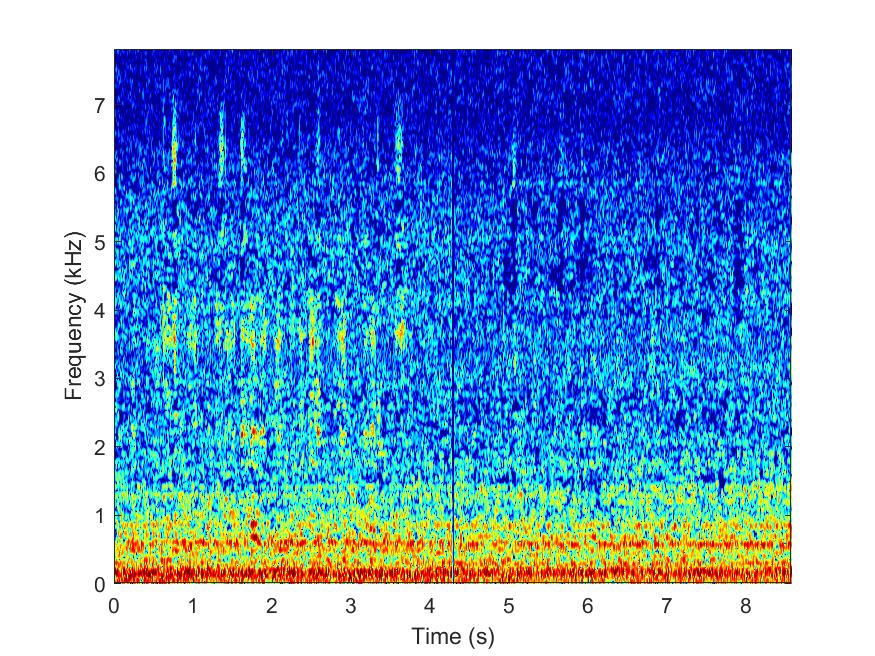 --> -->
|
Clean
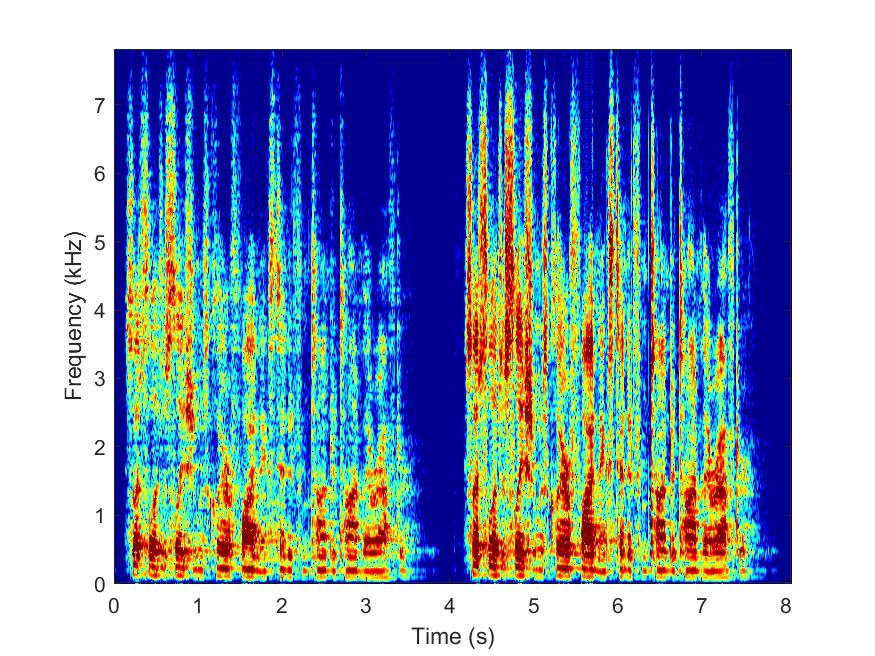 --> -->
|
Noisy
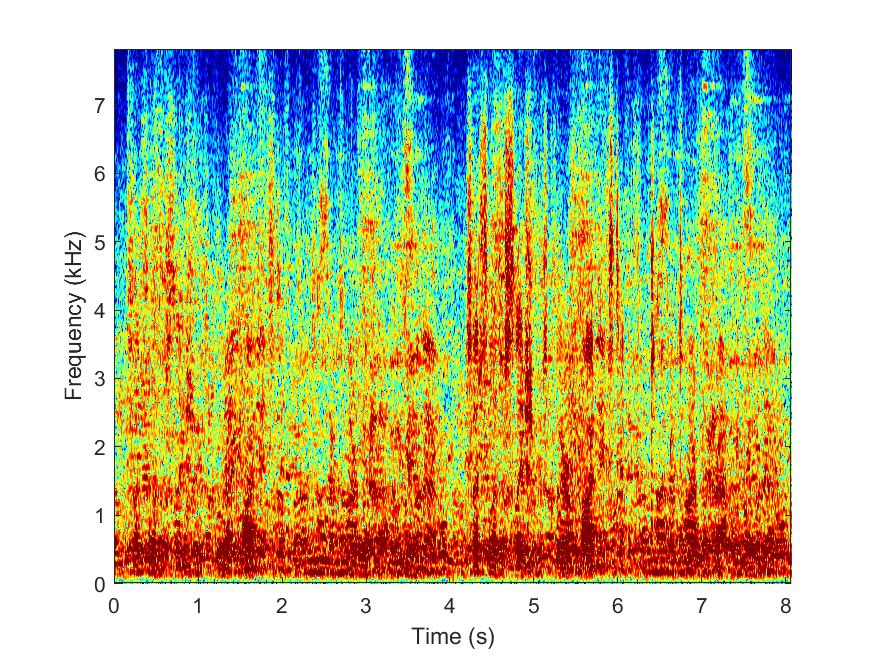 --> -->
|
Proposed
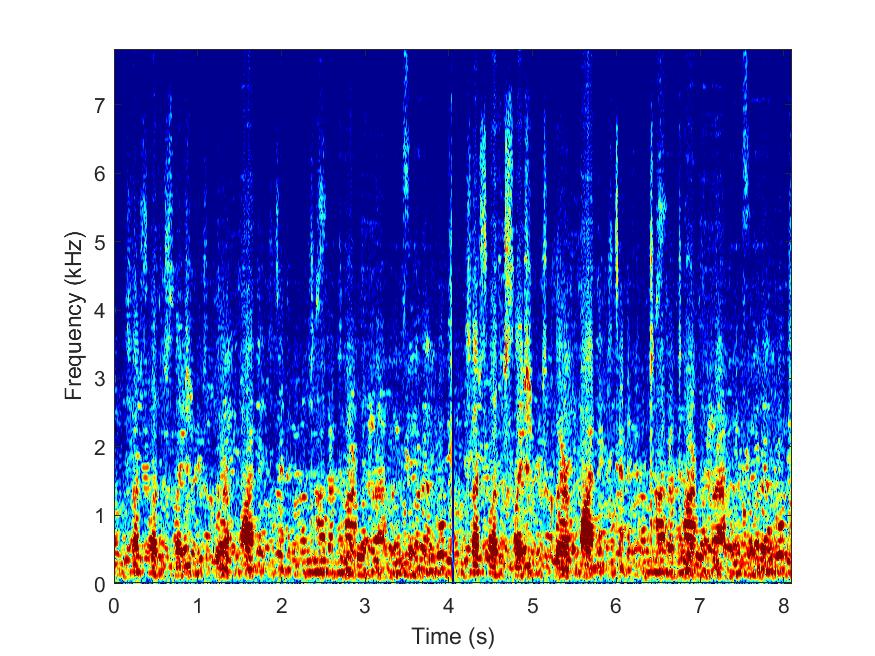 --> -->
|
MESSL
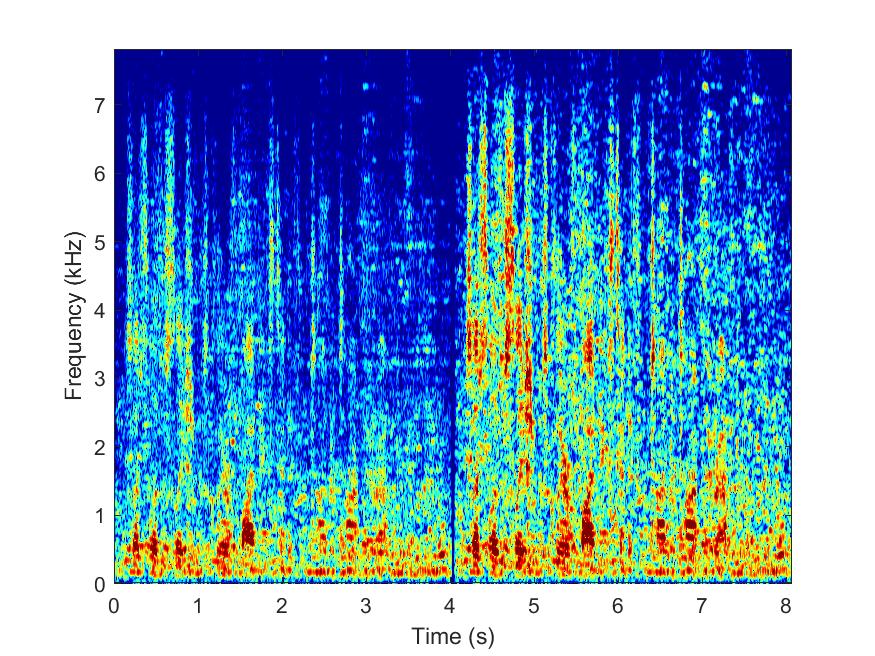 --> -->
|
RANSAC
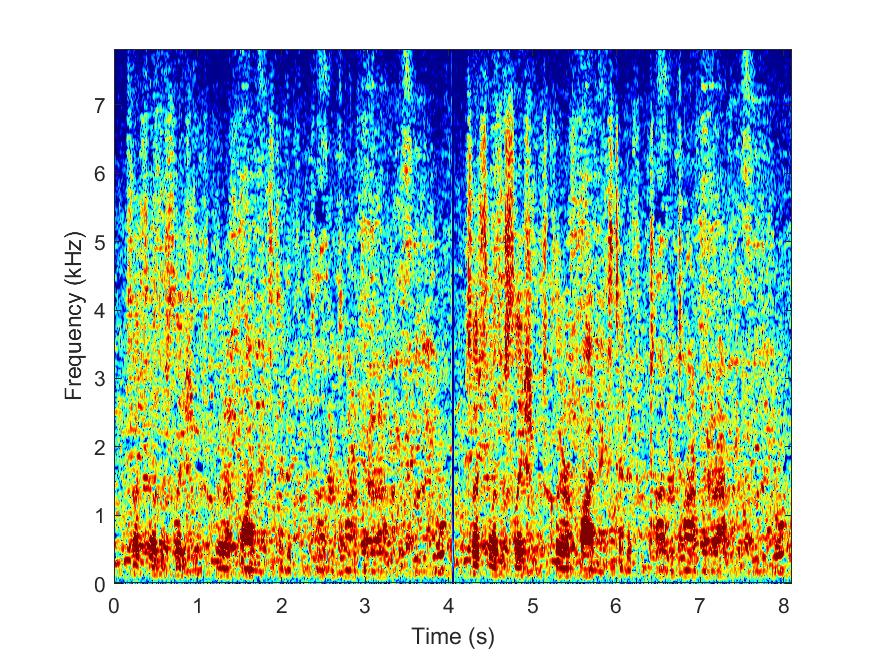 --> -->
|