"Overcoming Covariance Matrix Phase Sensitivity in Single-Channel Speech Enhancement with Correlated Spectral Components"
Johannes Stahl, Sean U.N. Wood, Pejman Mowlaee
- Audio samples -
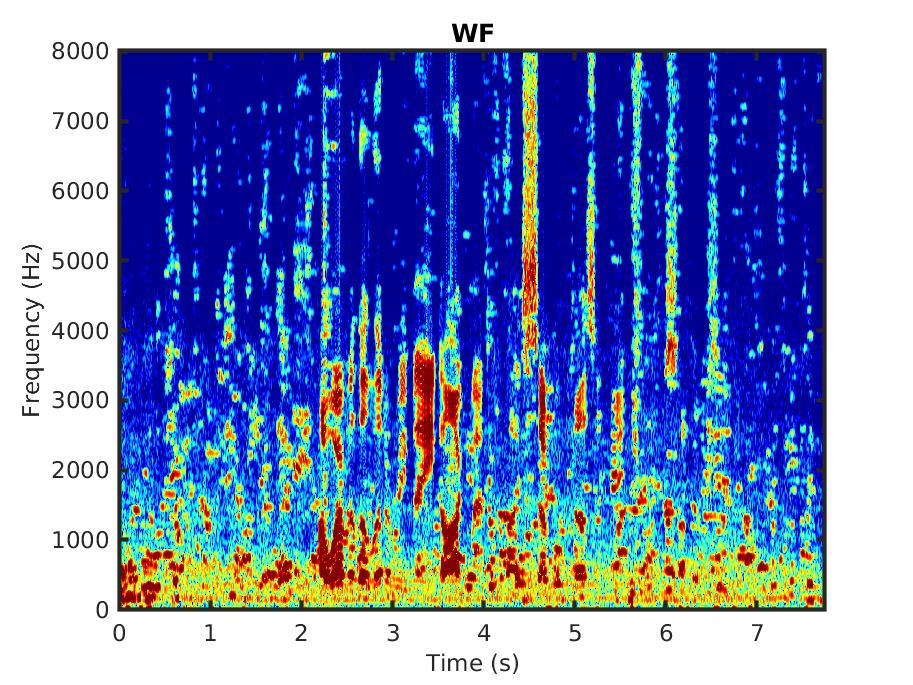
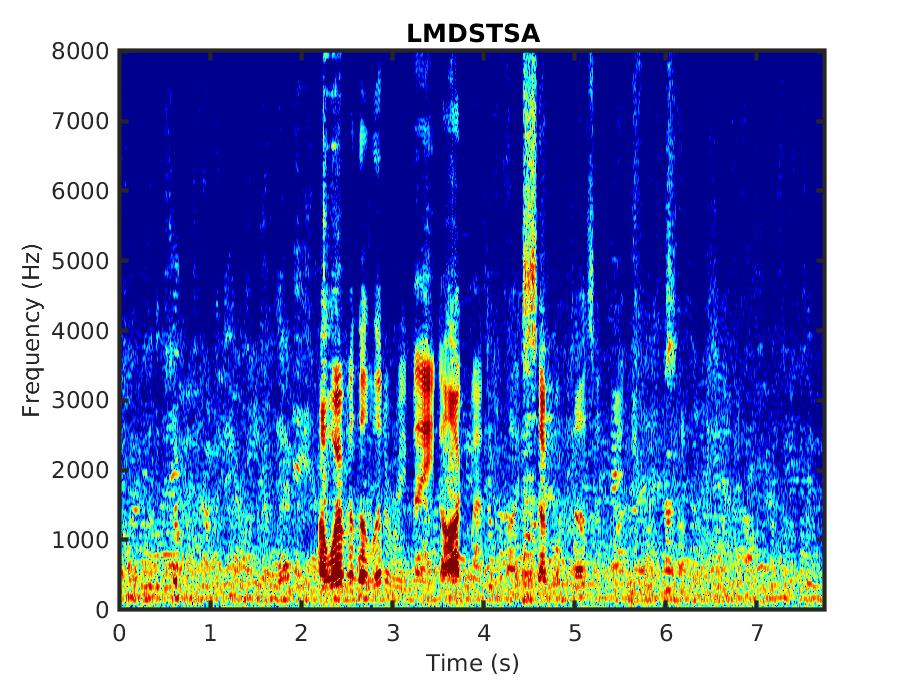
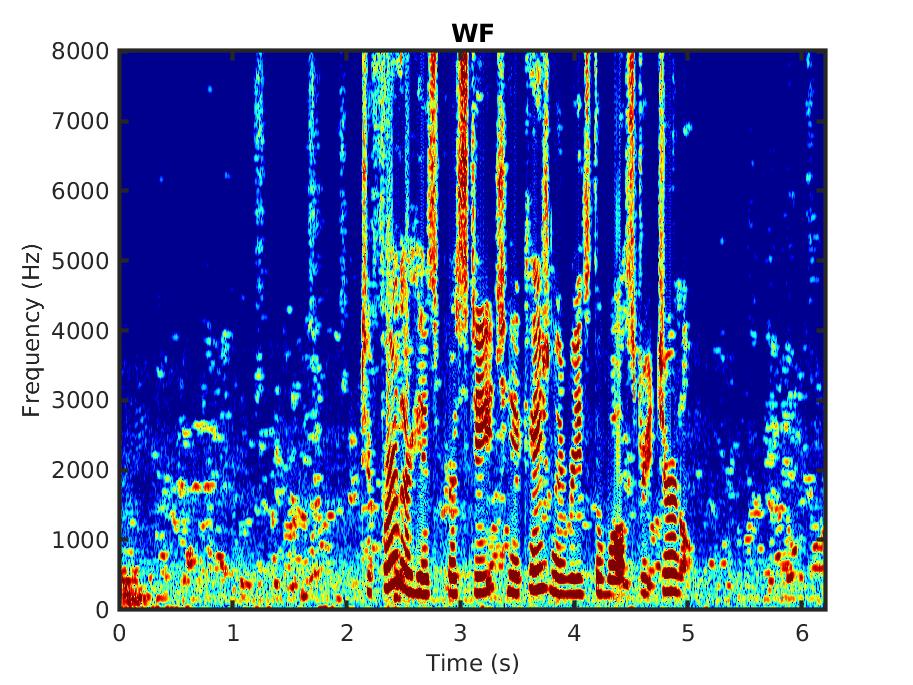
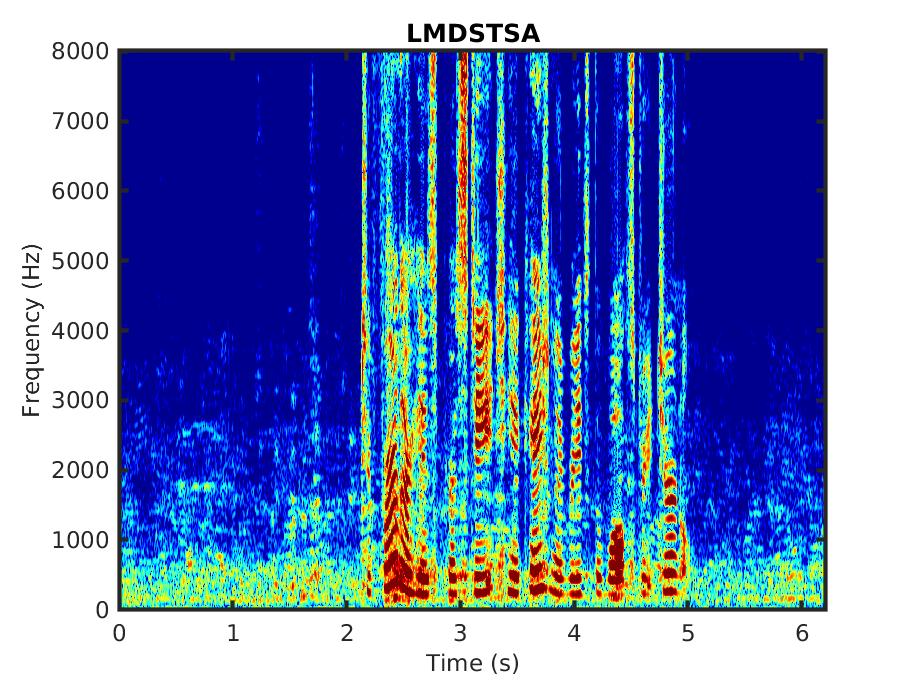
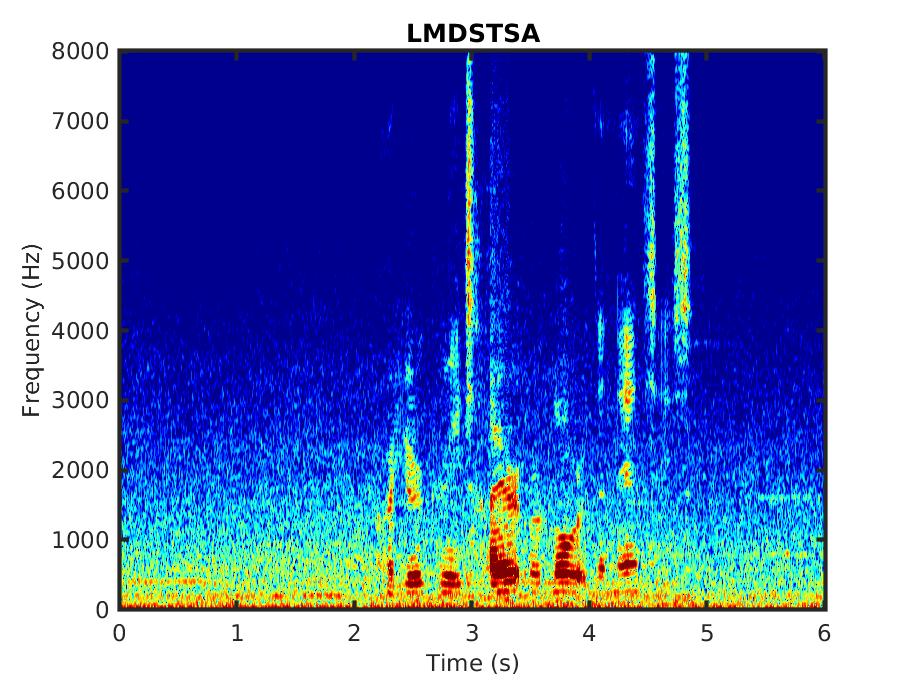
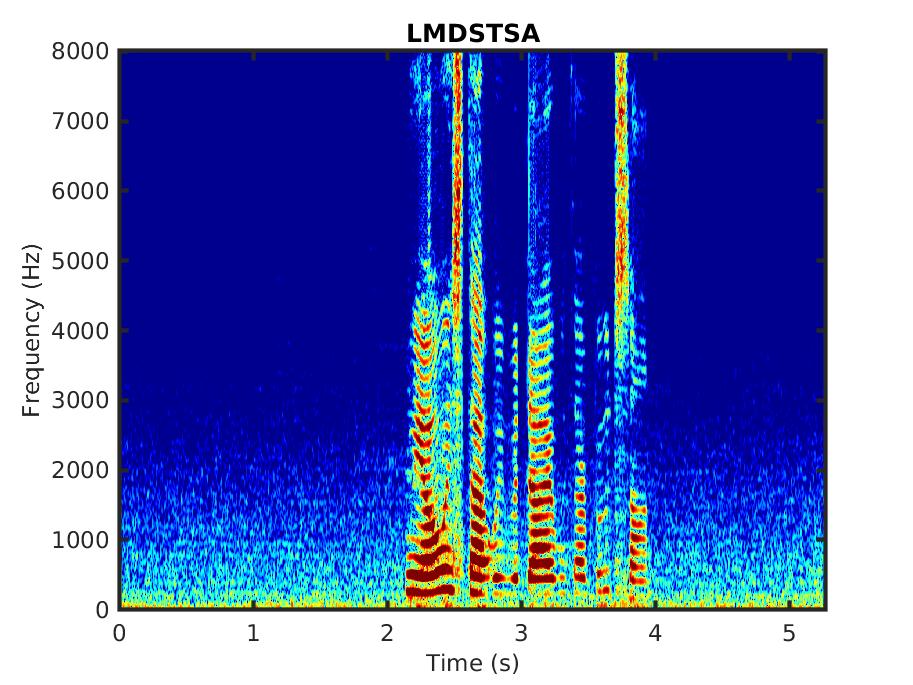
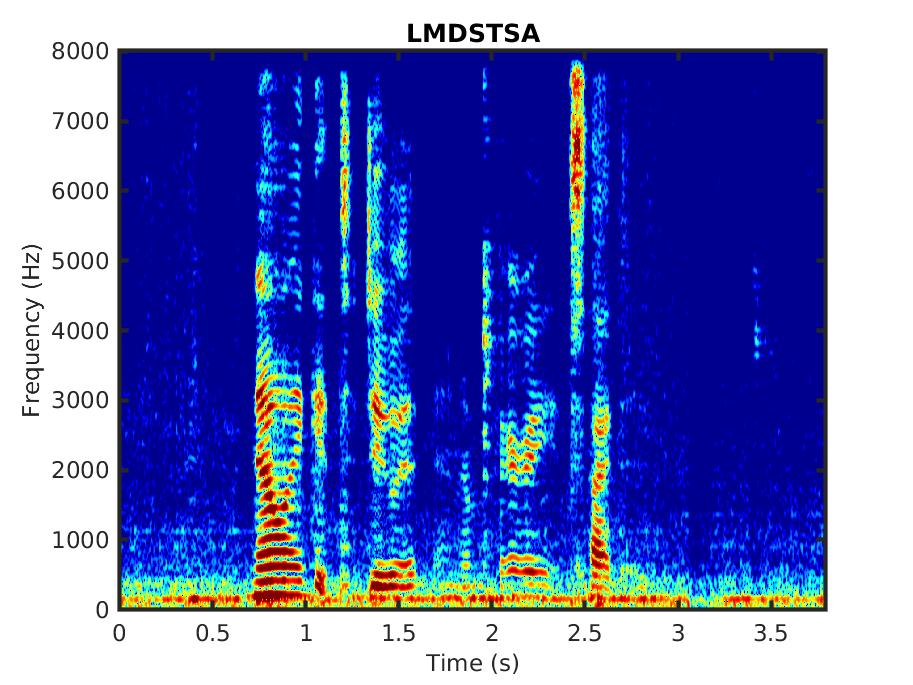
Below, we present some audio samples demonstrating the impact of the proposed linear MMSE STSA estimator that takes into account correlated spectral components (LMDSTSA).
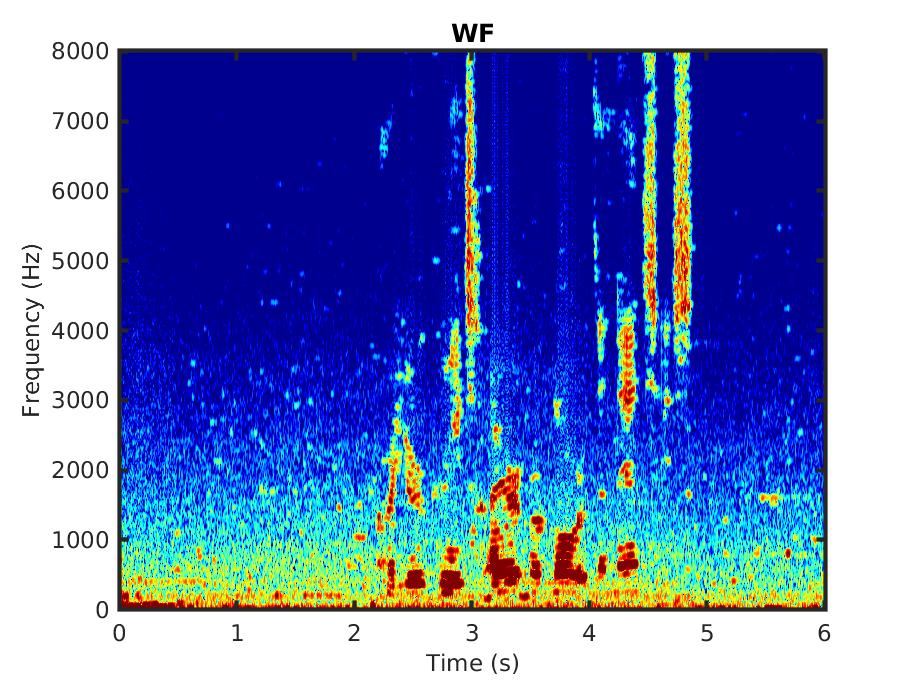
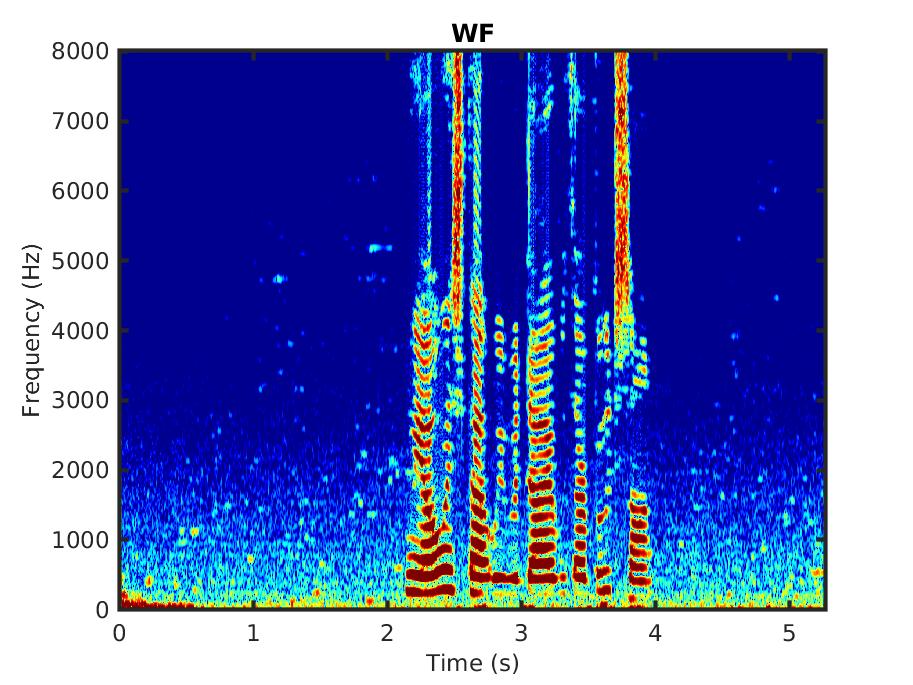
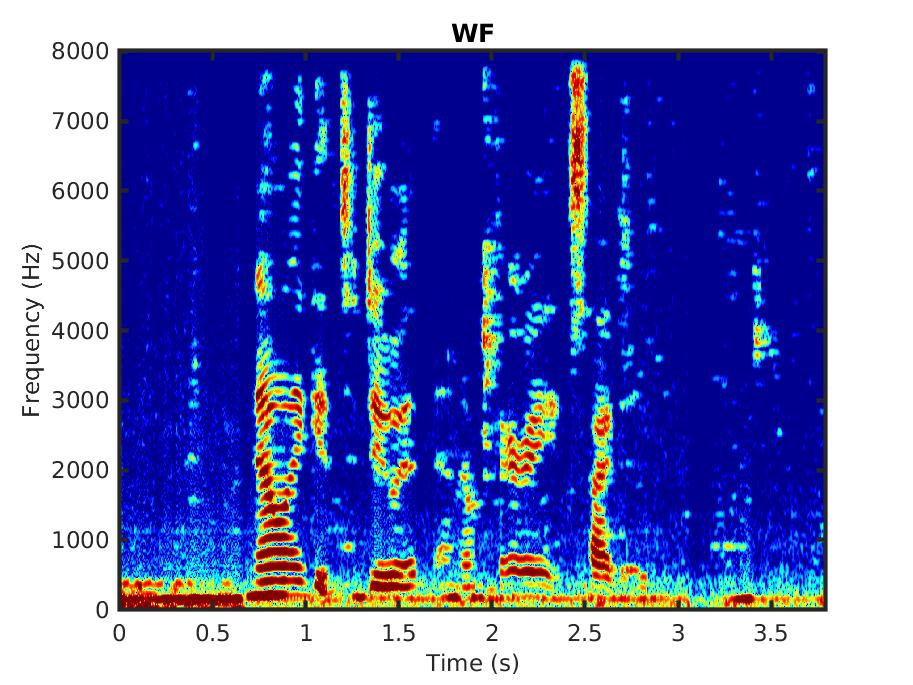
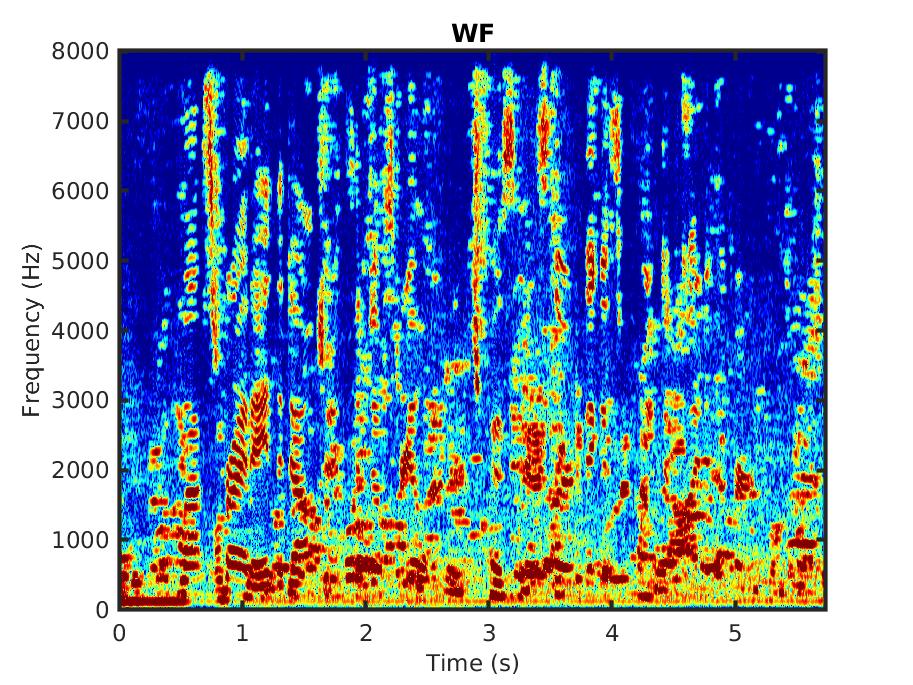
For comparison we also present the outcome of applying the standard Wiener filter (WF).
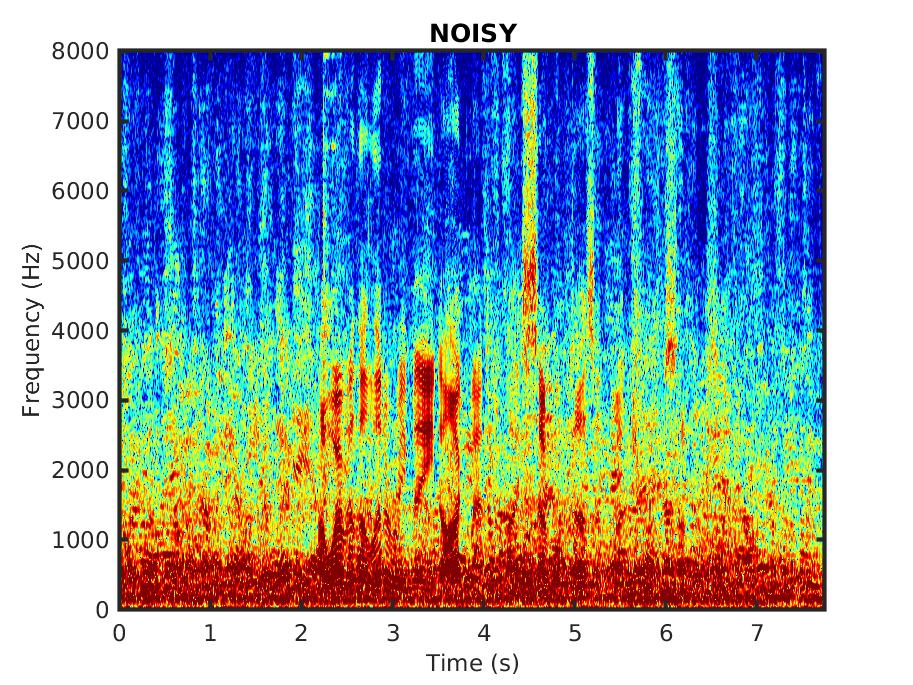
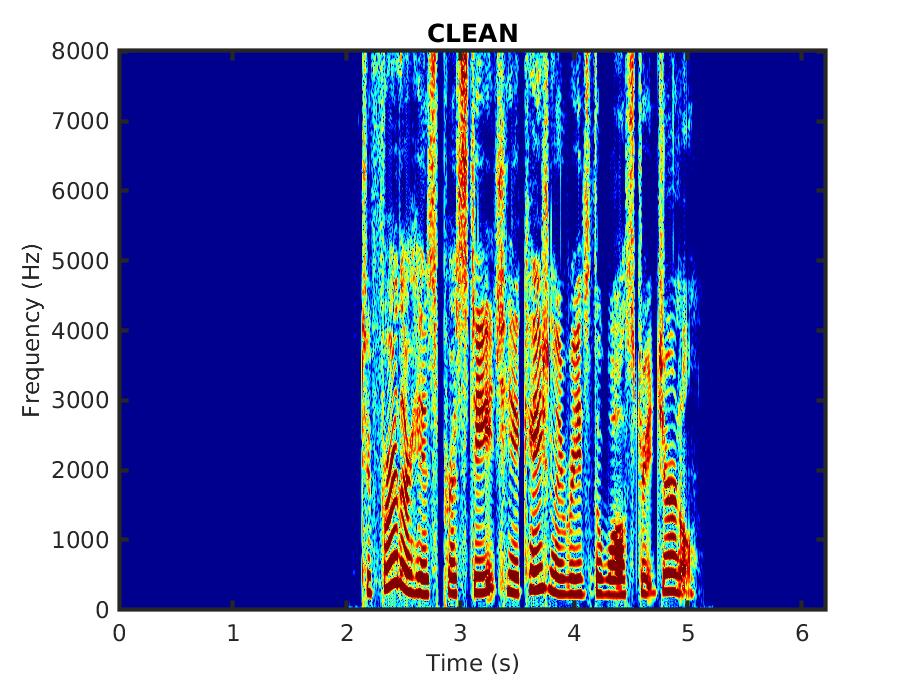
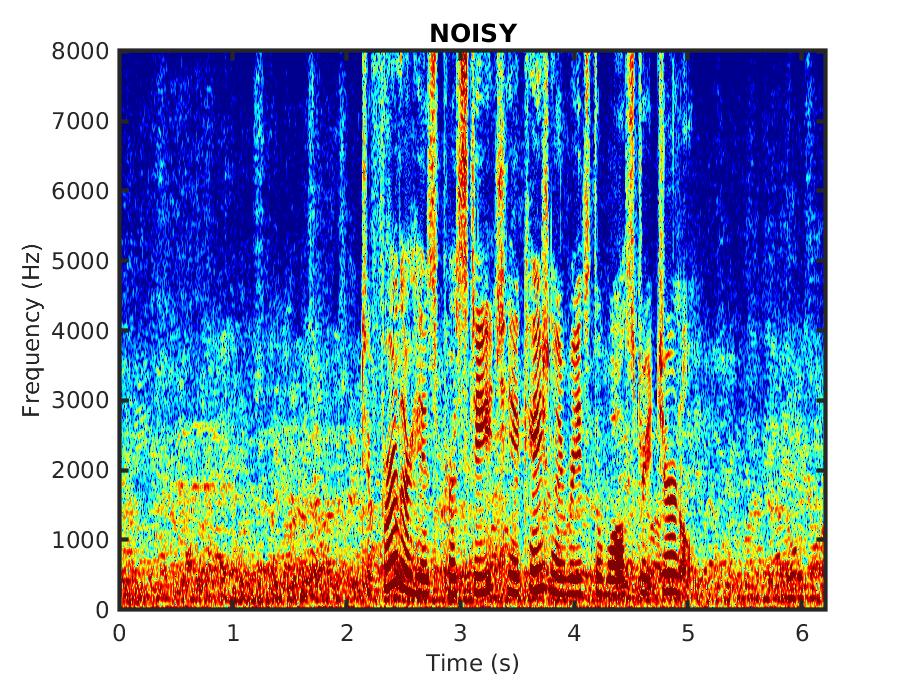
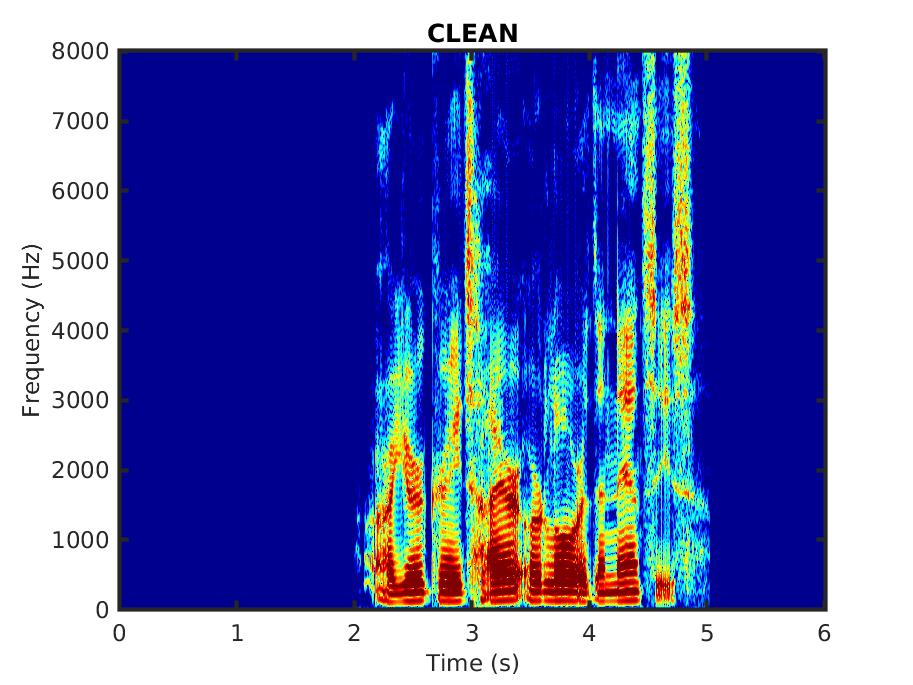
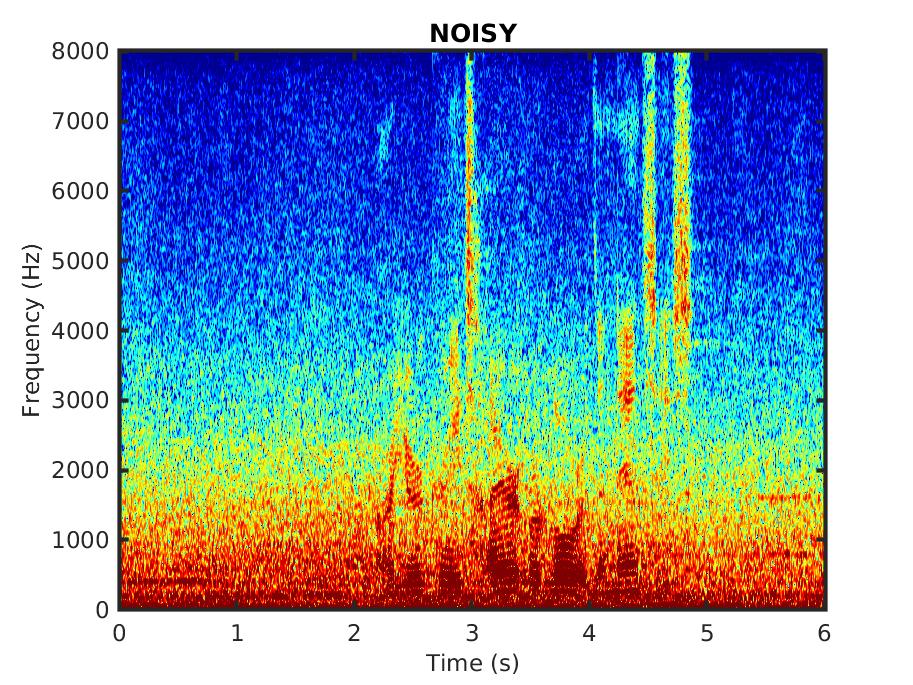
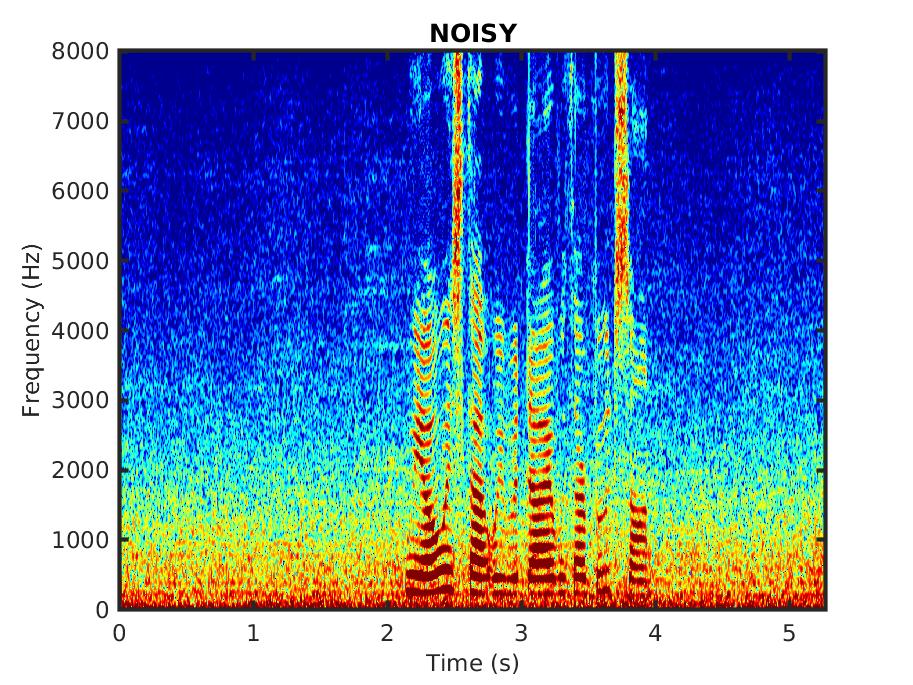
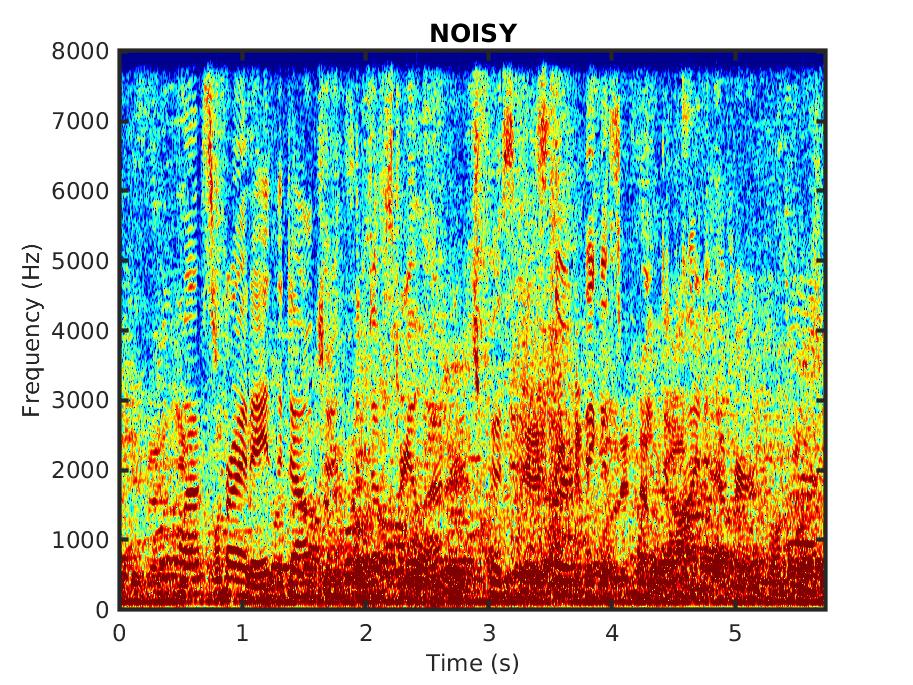
The audio samples consist of utterances spoken by male and female speakers, corrupted in different noise types.
Male speaker: ''However, the litter remained, augmented by several dozen lunchroom suppers.'' in babble noise, SNR = 0 dB:
Female speaker: ''To further his prestige, he occasionally reads the Wall Street Journal.'' in babble noise, SNR = 10 dB:
Male speaker: ''Are your grades higher or lower than Nancy's?'' in factory noise, SNR = 0 dB:
Female speaker: ''We always thought we would die with our boots on.'' in factory noise, SNR = 10 dB:
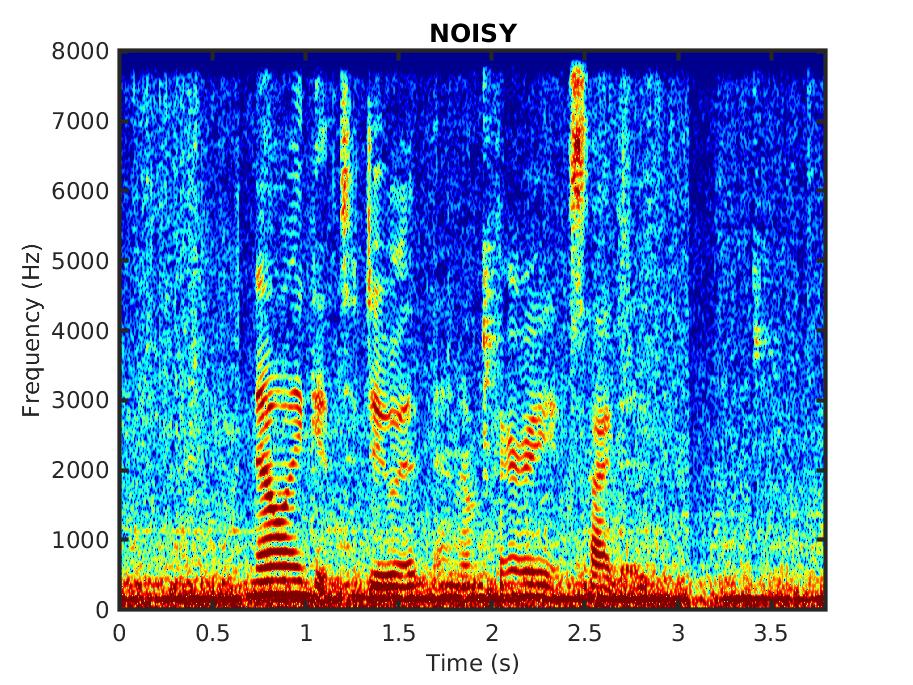
Female speaker in a bus as an example for a real-world scenario. The recording was part of the Chime 4 challenge [1].
Female speaker in a cafe as an example for a real-world scenario. The recording was part of the Chime 4 challenge [1].
[1]Emmanuel Vincent, Shinji Watanabe, Aditya Arie Nugraha, Jon Barker, and Ricard Marxer, "An analysis of environment, microphone and data simulation mismatches in robust speech recognition", in Computer Speech and Language, vol. 46, pp. 535-557, 2016 [website].