Phase Estimation for Improved Single-Channel Source Separation Based on Time-Frequency Masking, JASA, vol. 141, pp. 46-68, 2017 (doi: http://dx.doi.org/10.1121/1.4986647)
- Audio samples - Full text
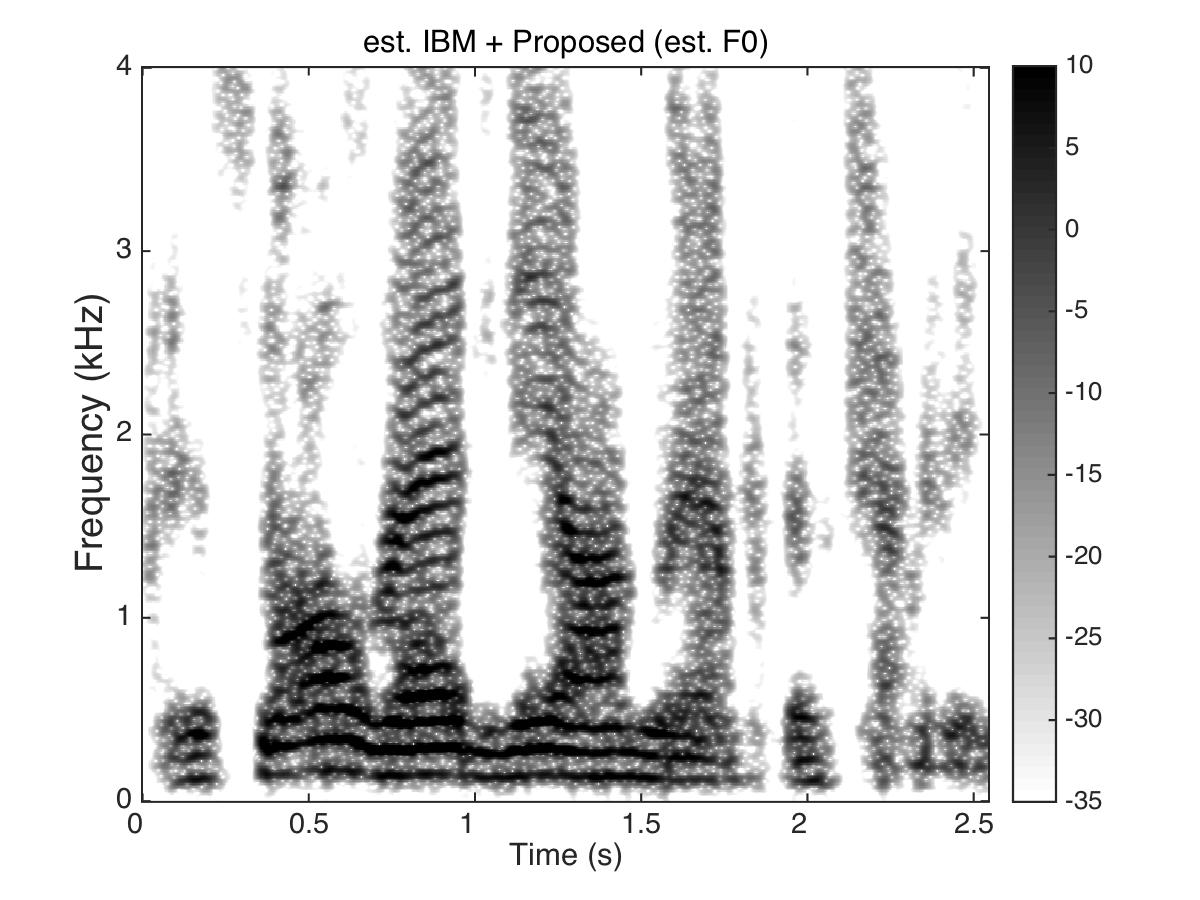
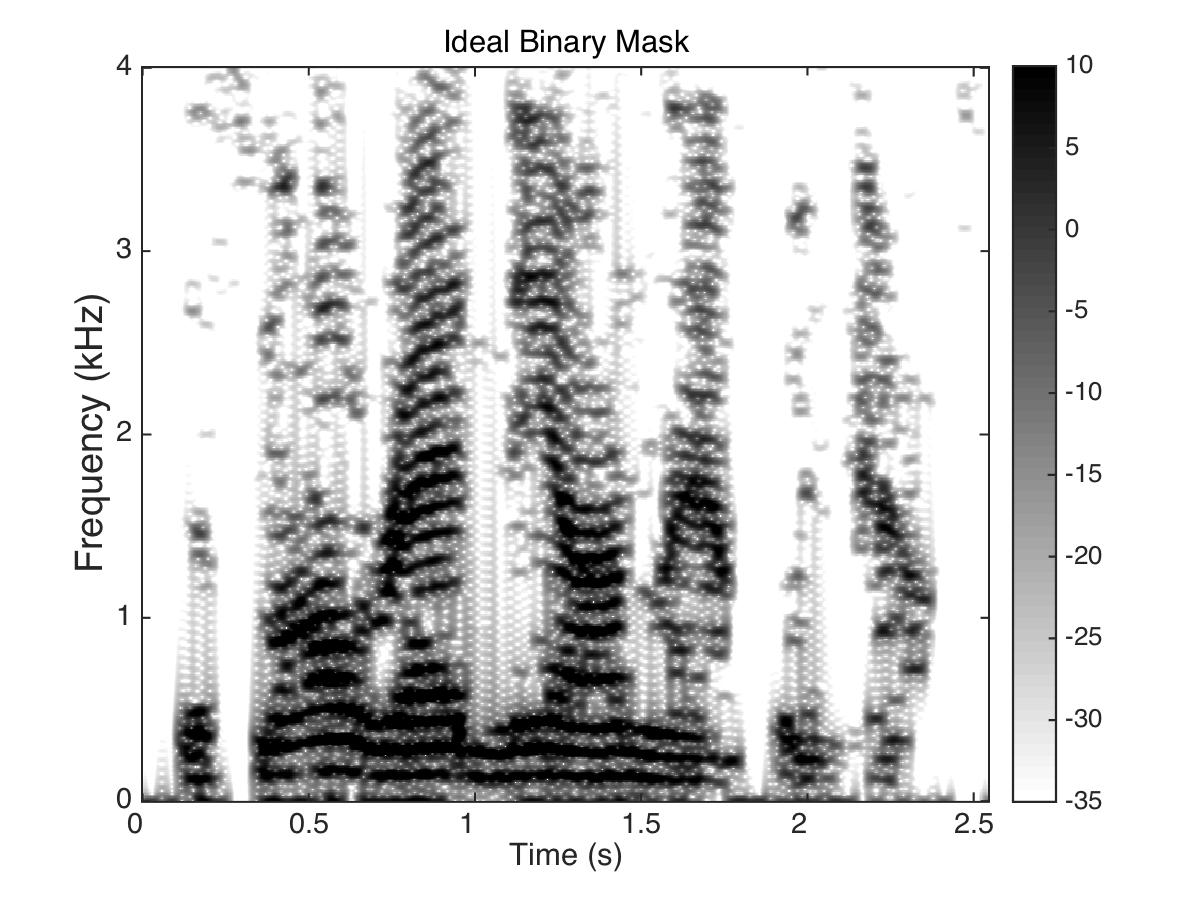
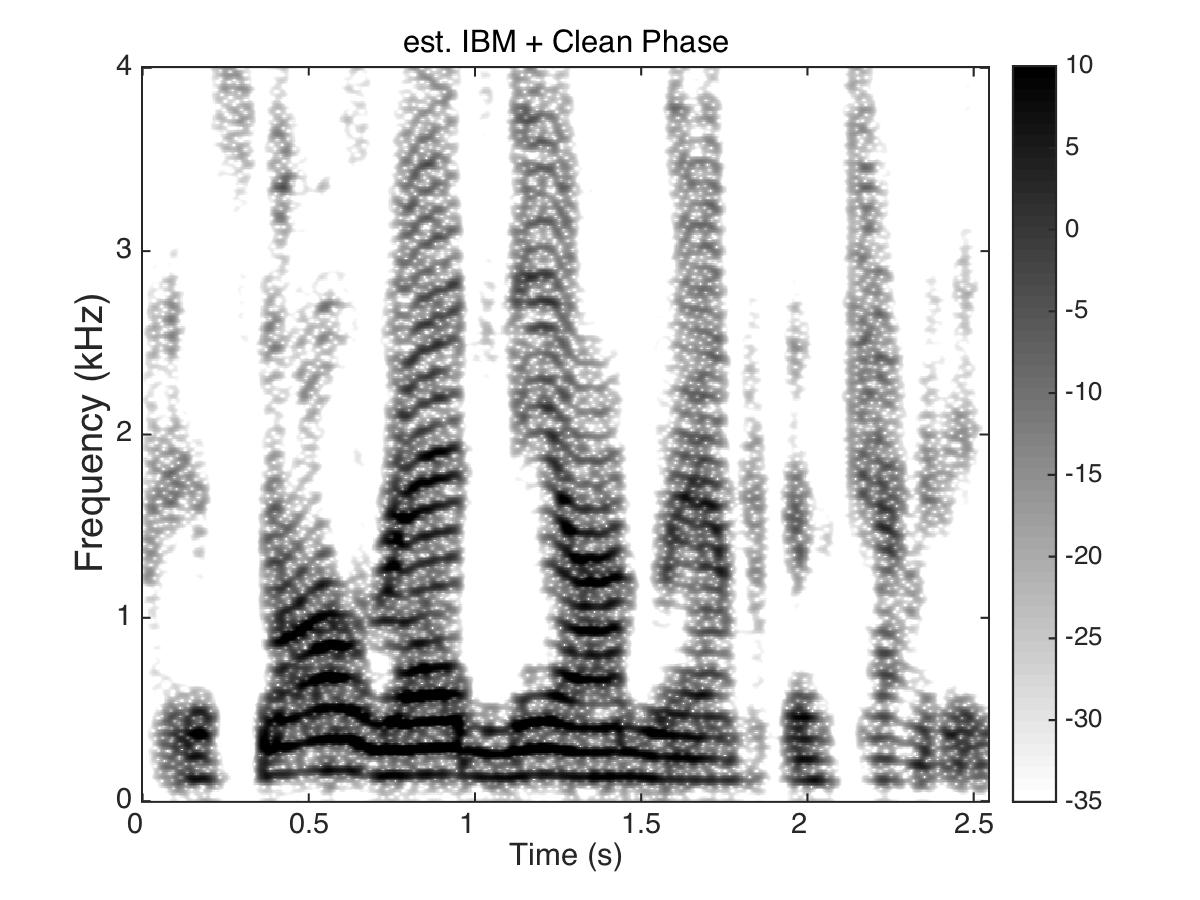
- Phase enhancement (PE) combined with Time-Frequency Masking (TFM) -
Experiment One
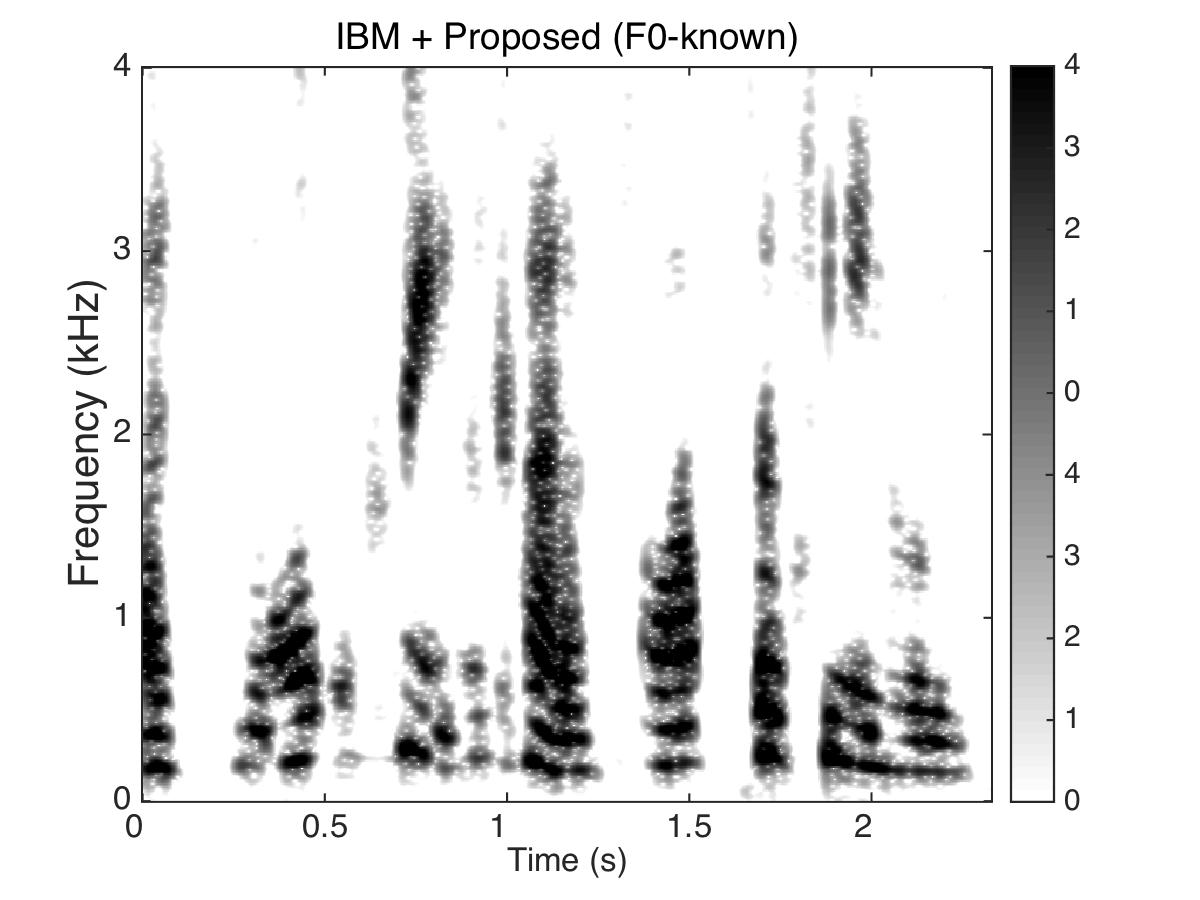
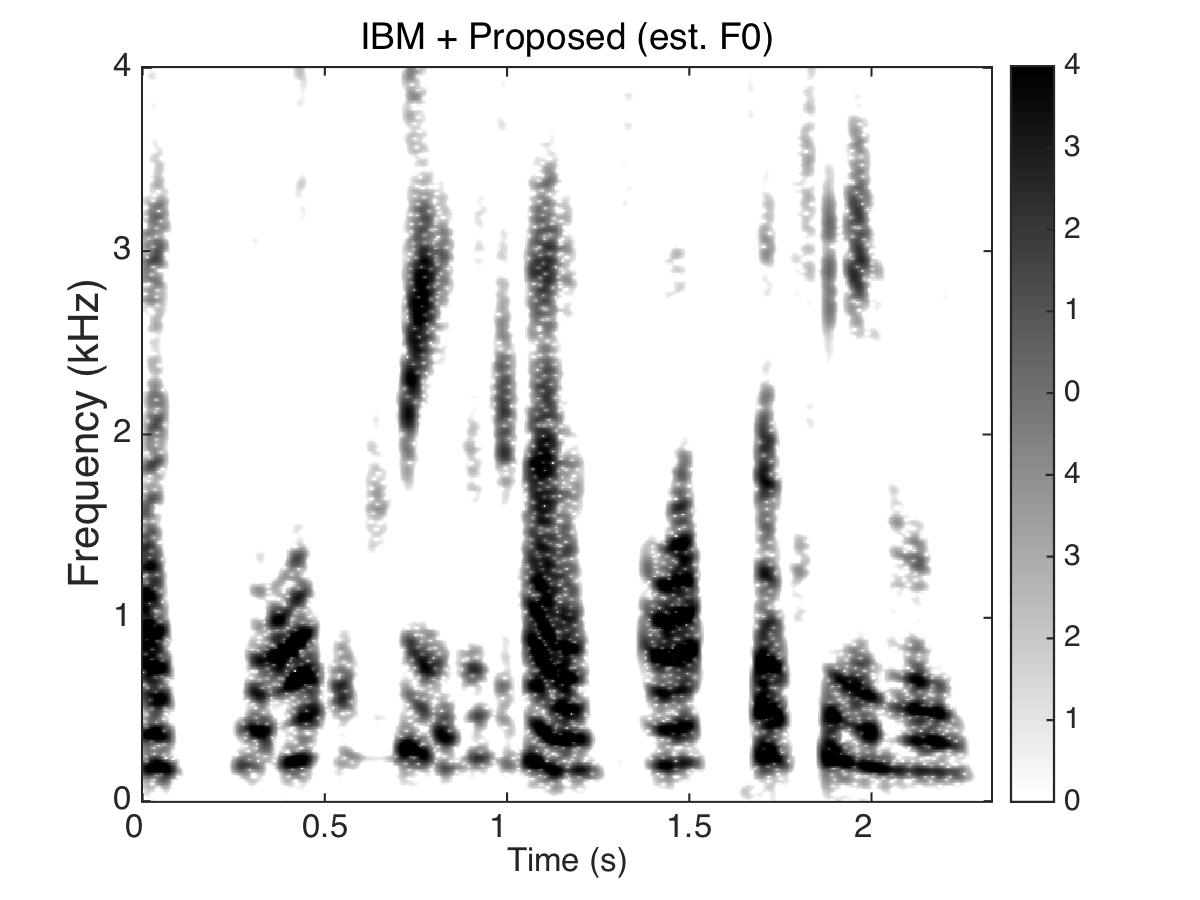
Estimated Binary Mask
Male Utter + Speech Shaped Noise (SSN) at SNR = 0 (dB)
Uttering: "The small red neon lamp went out"
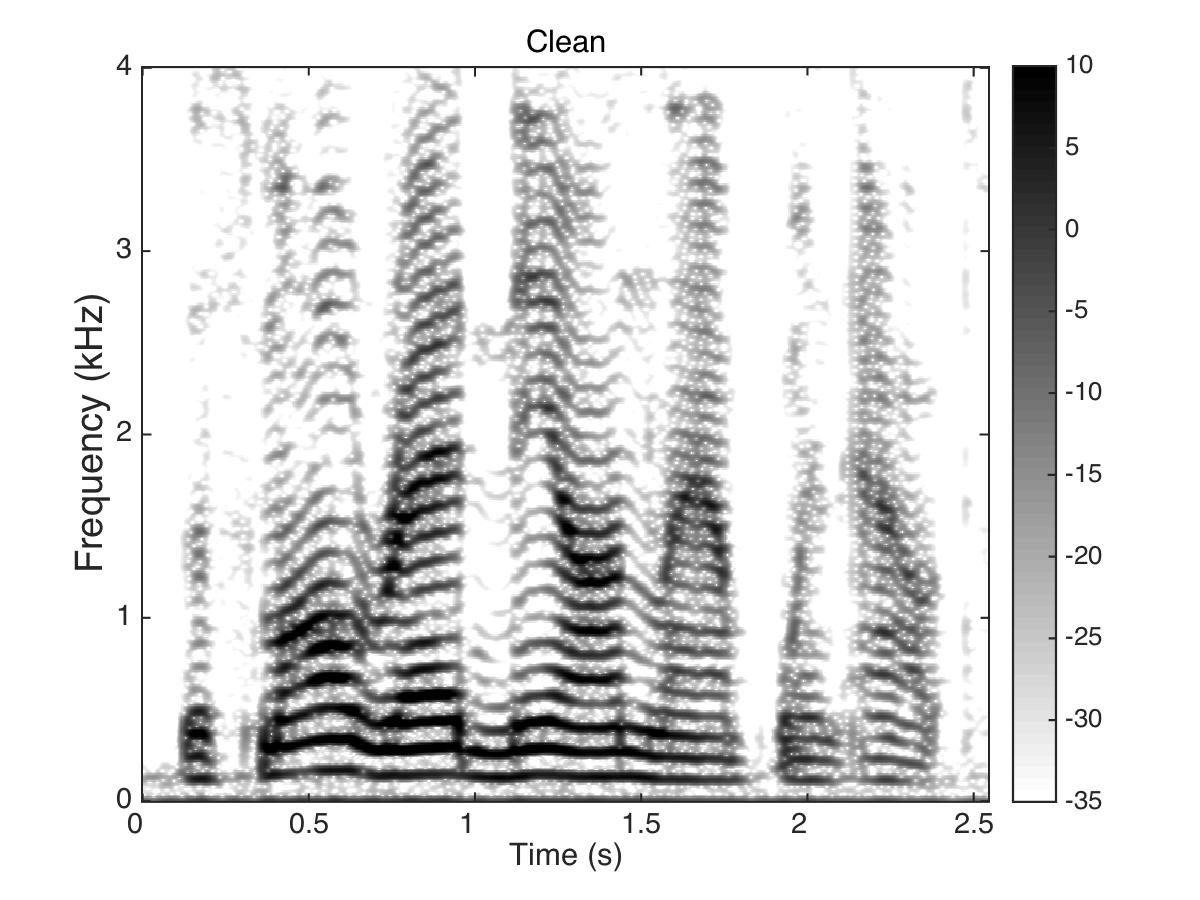
|
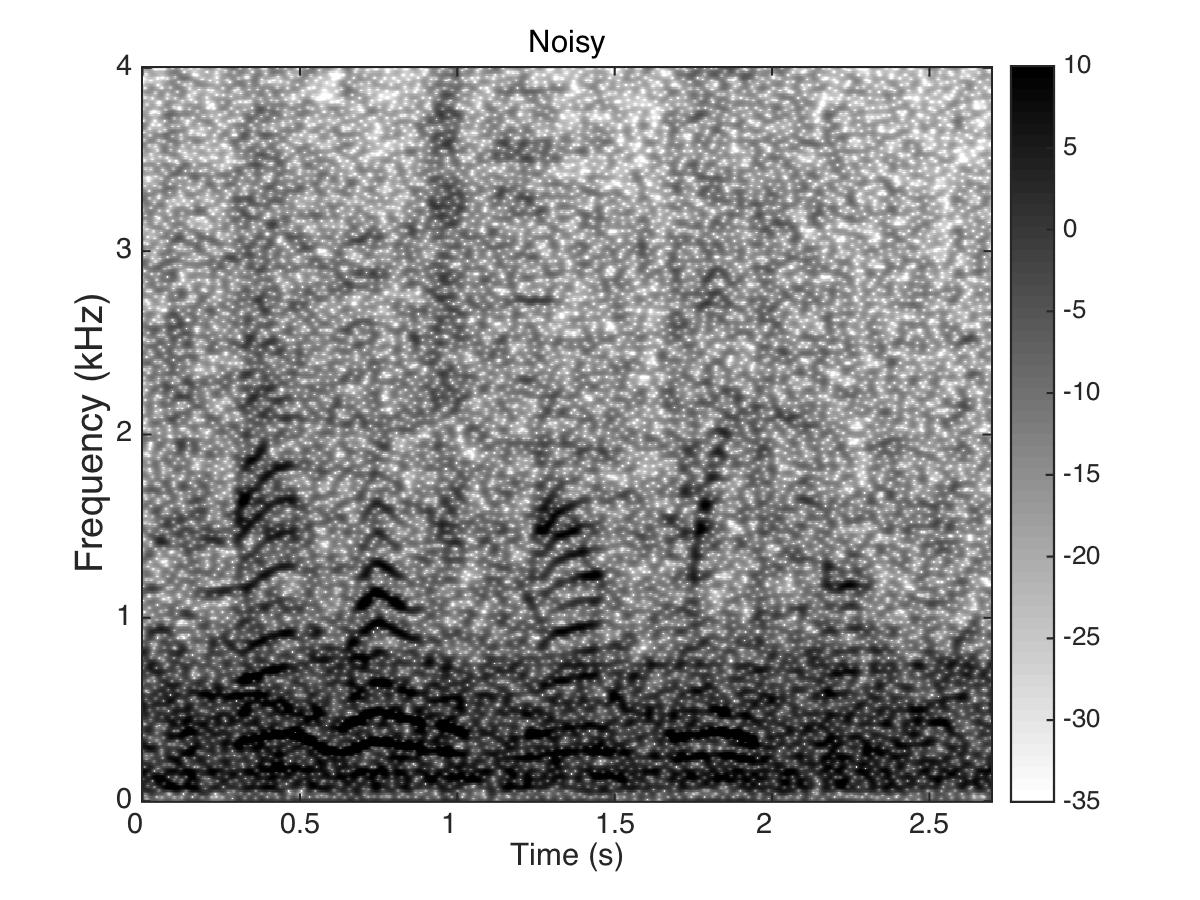
|
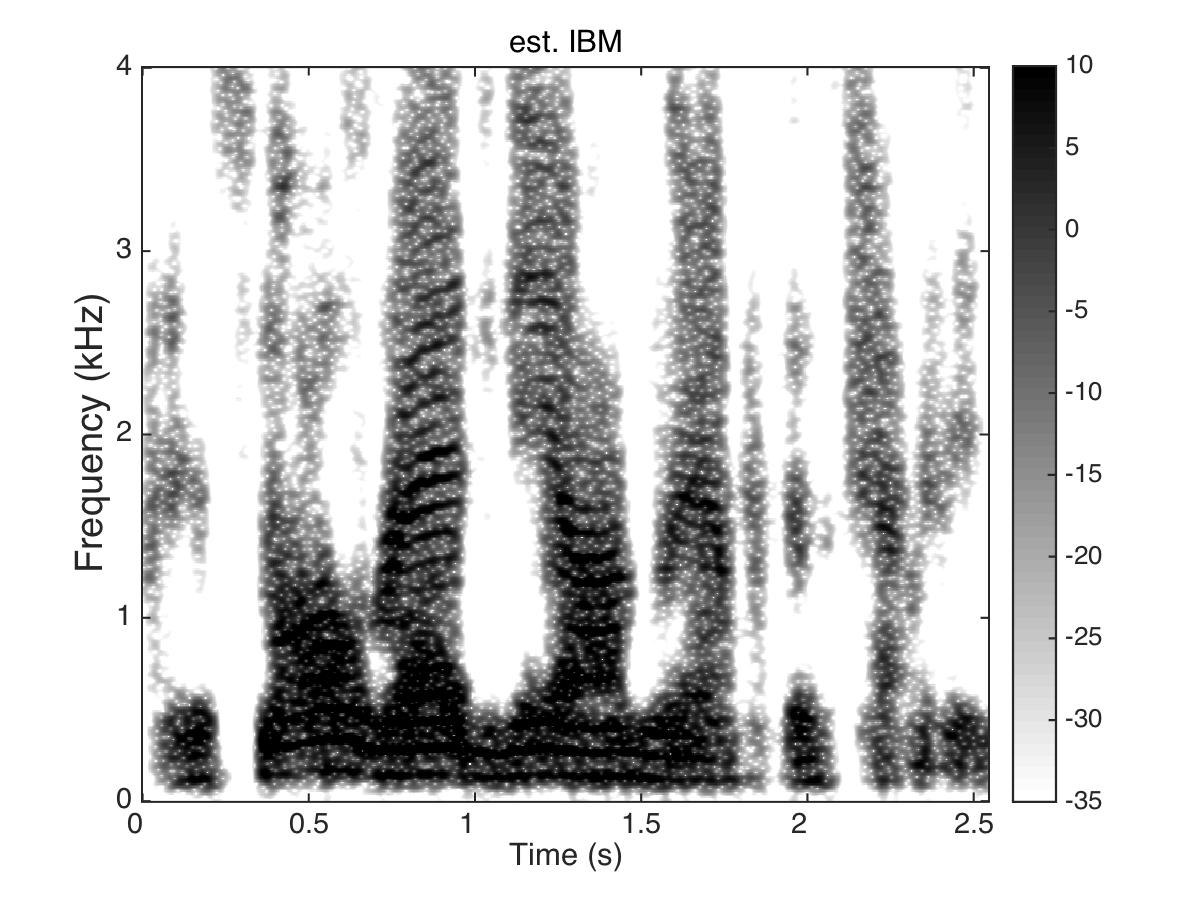
|
|
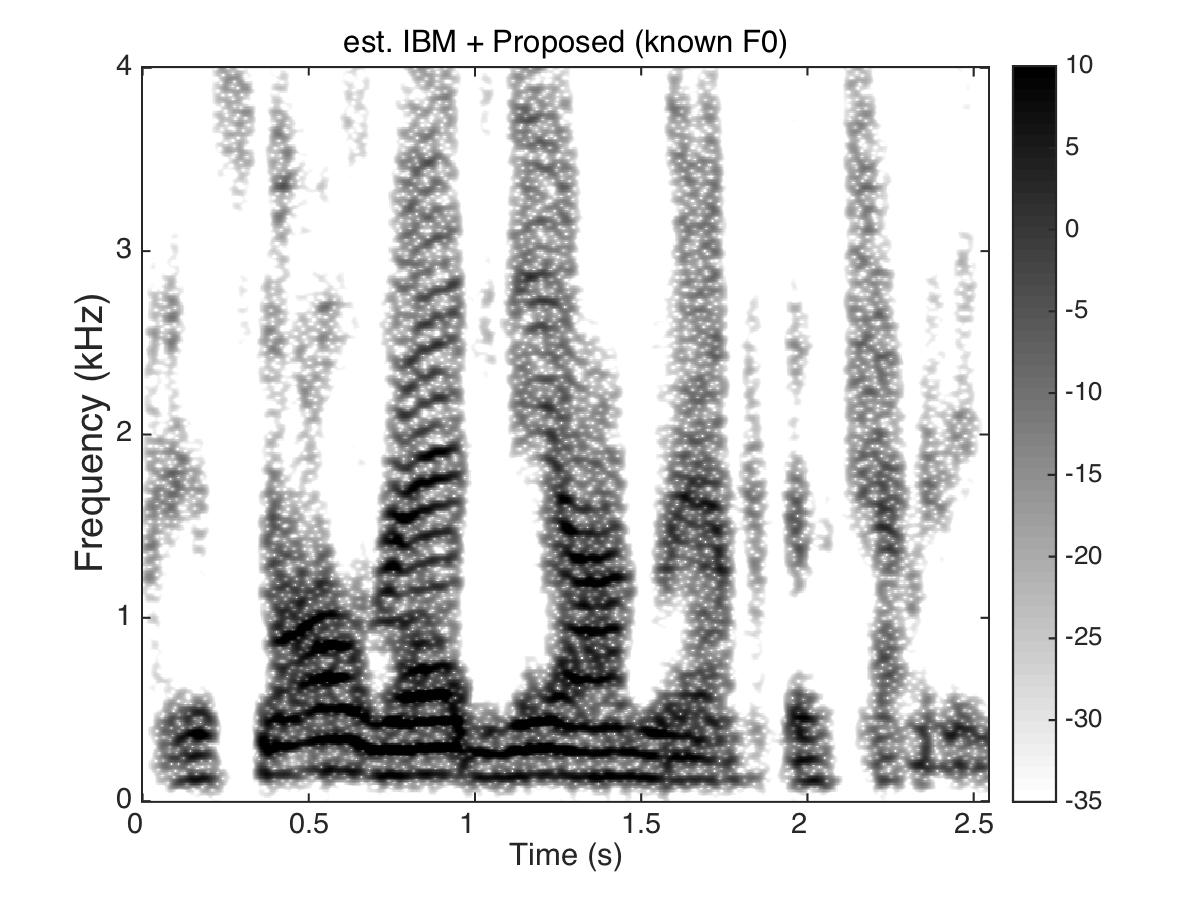
|
|
|
|
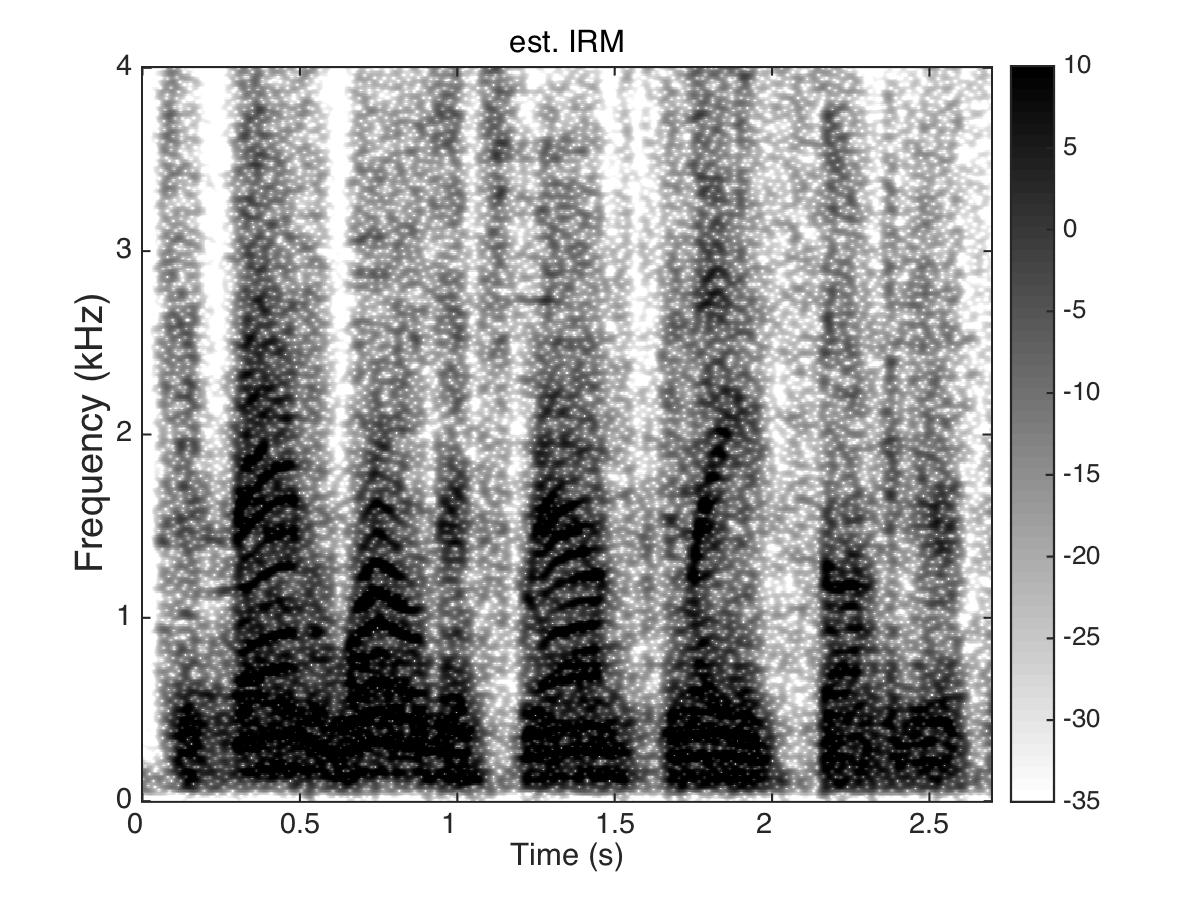
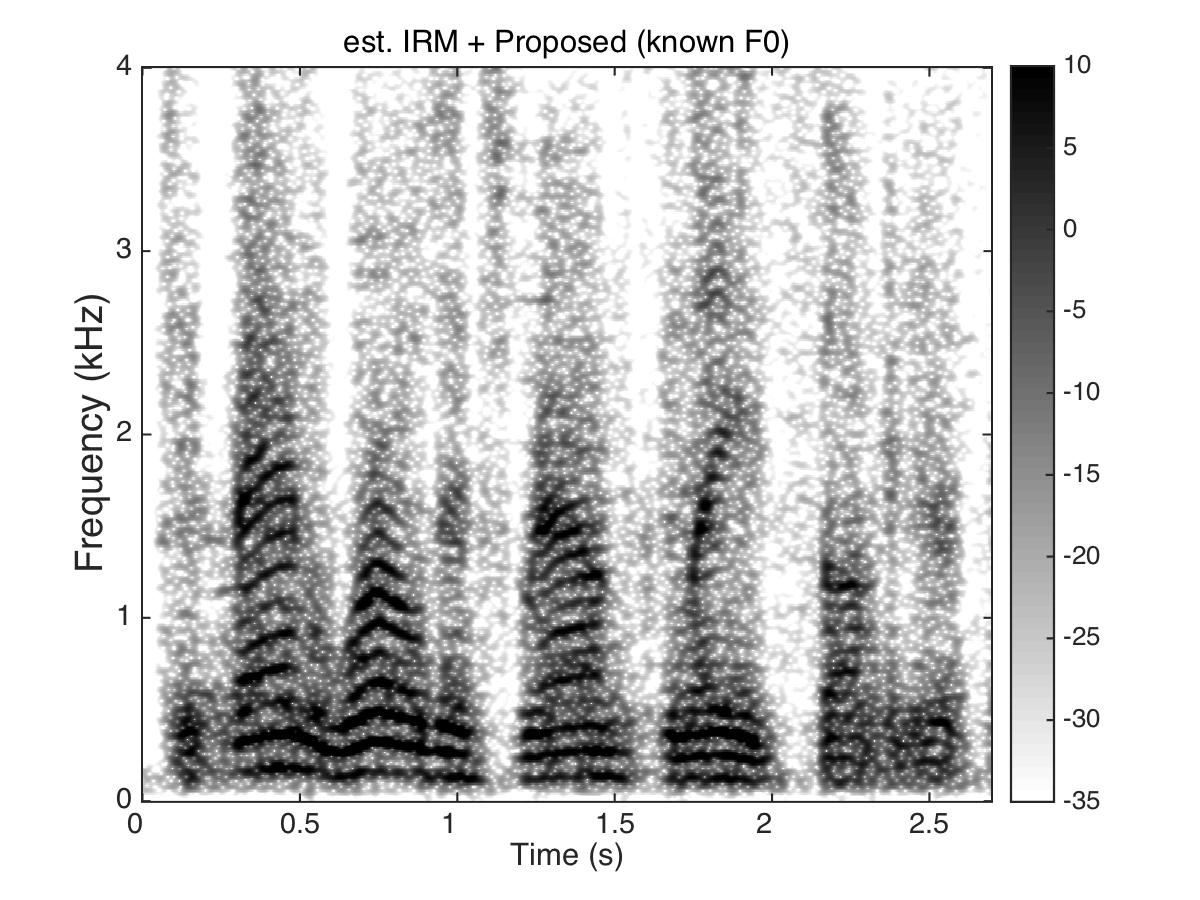
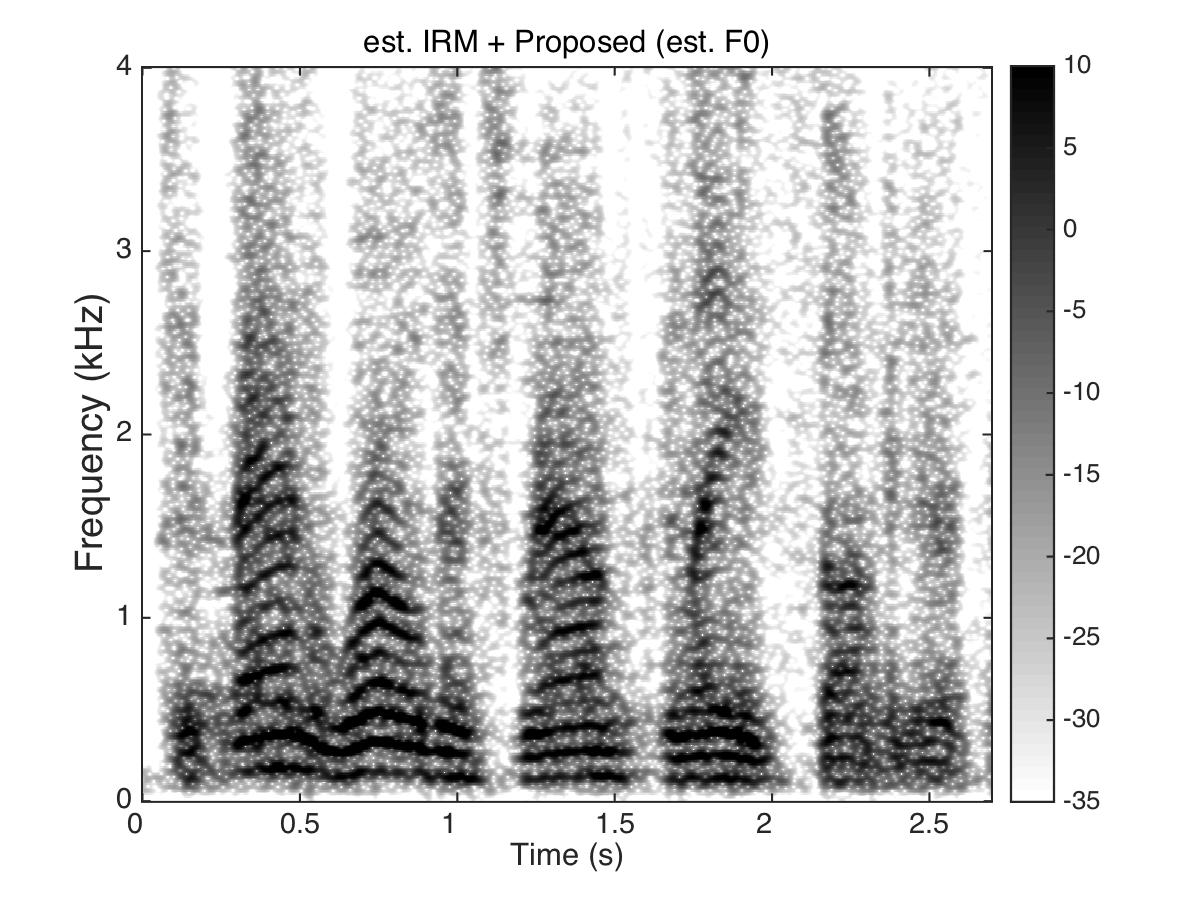
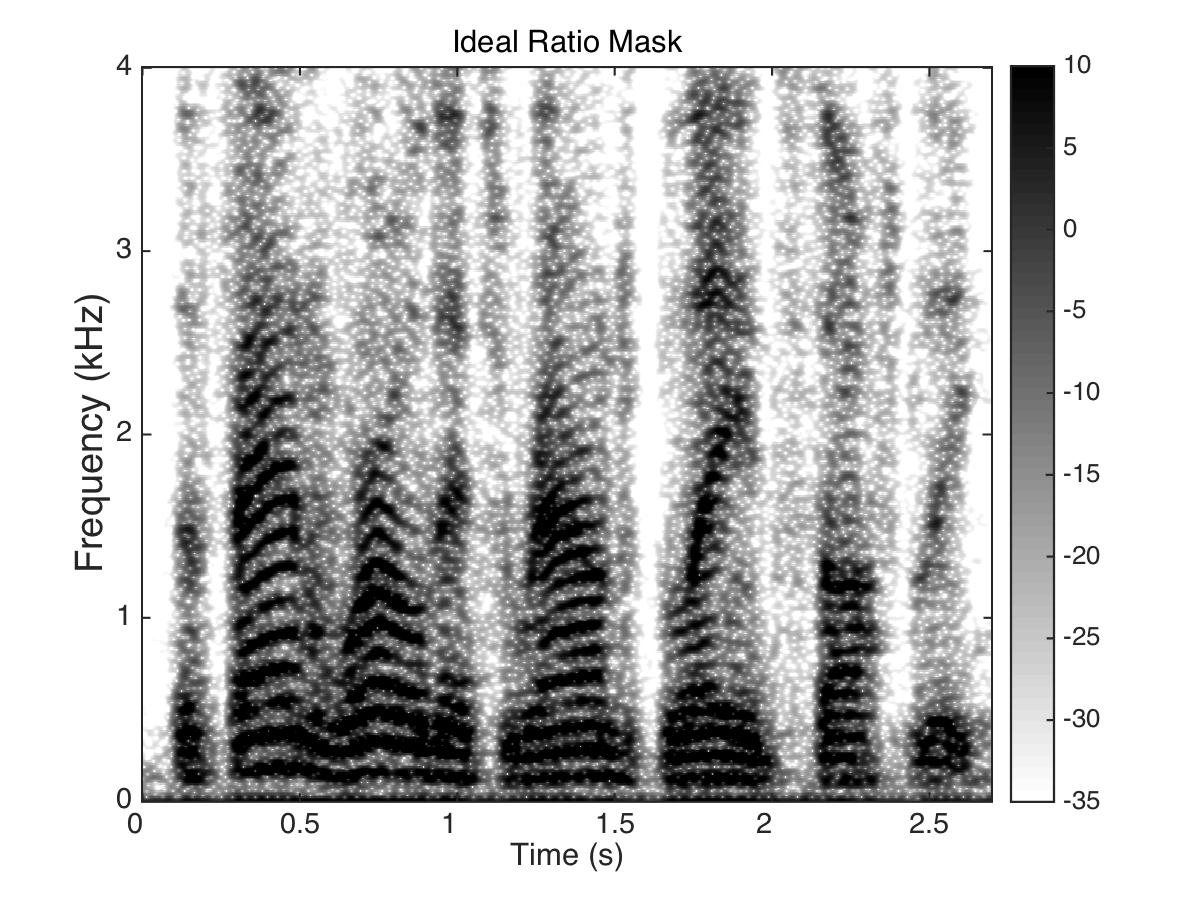
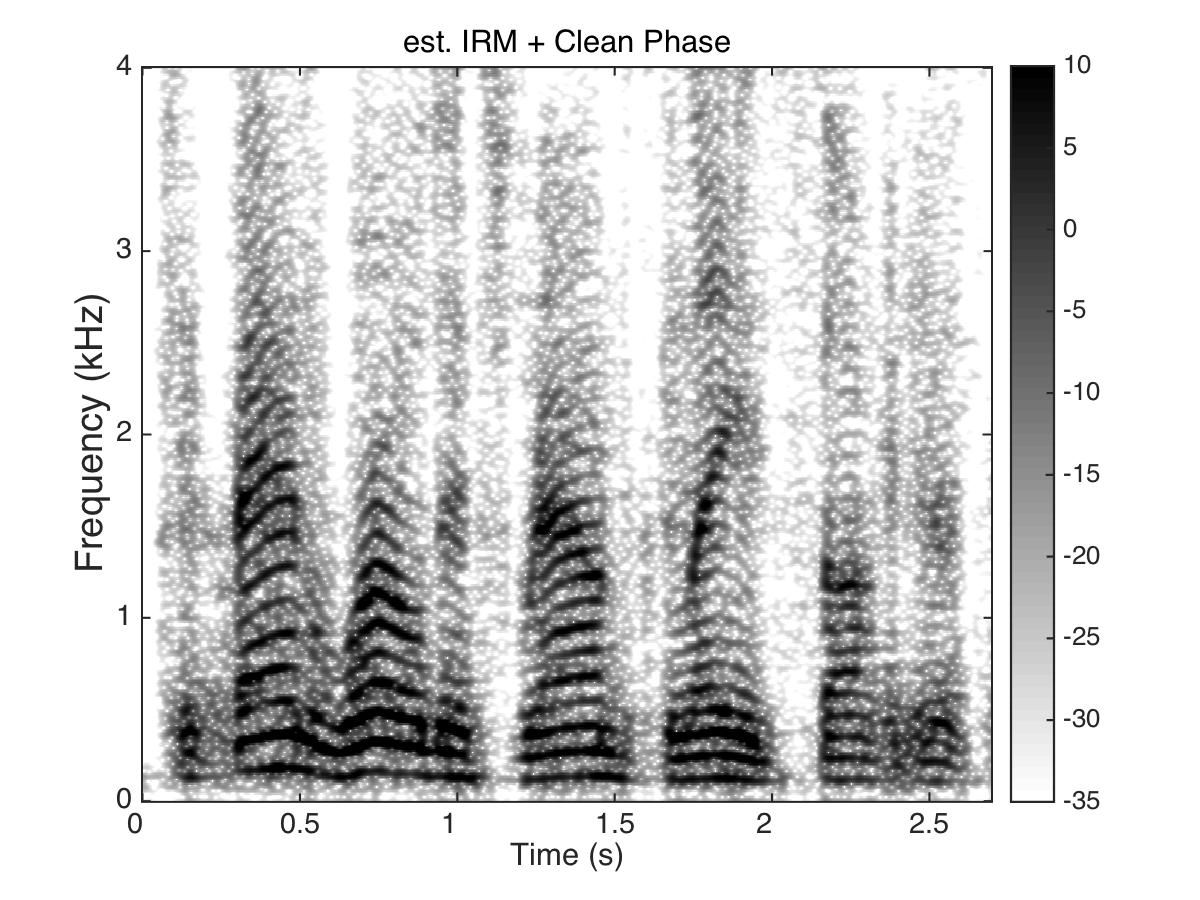
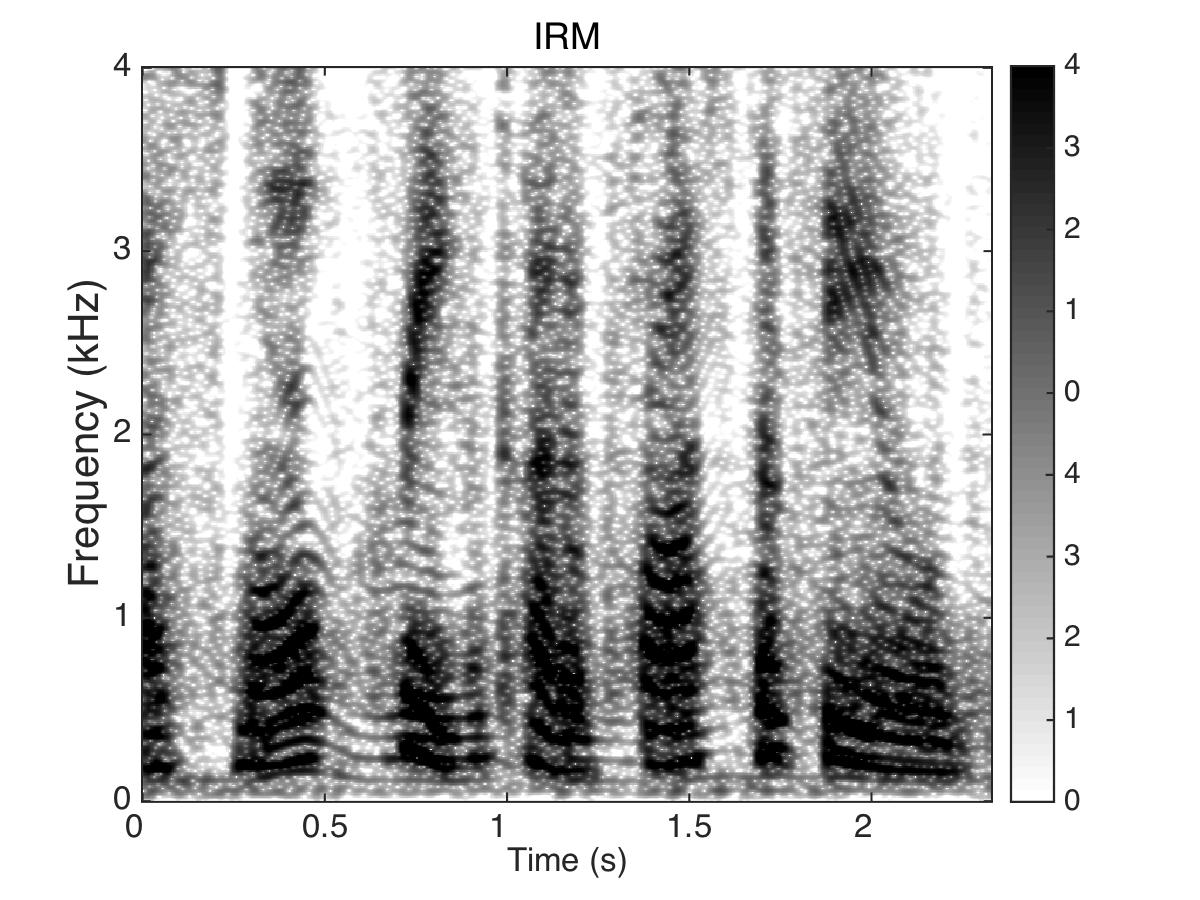
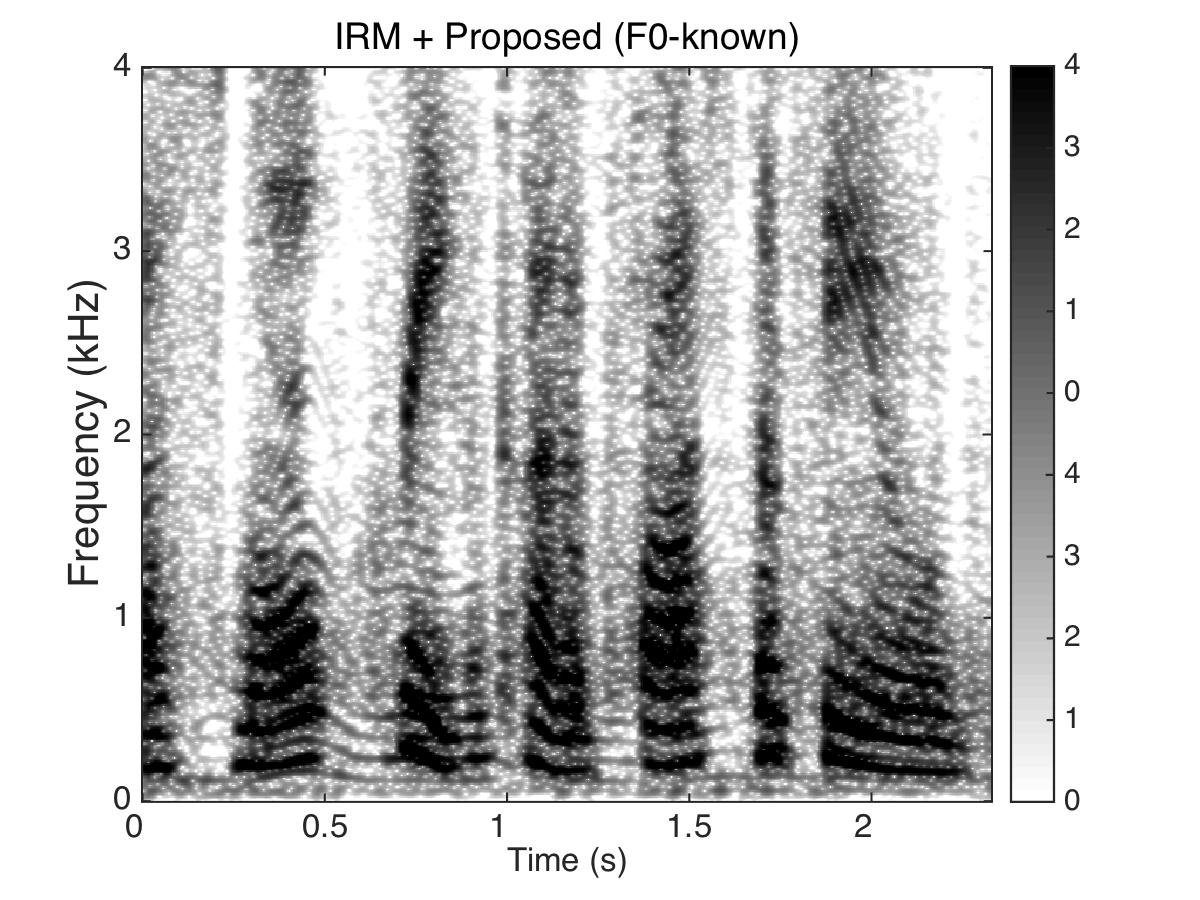
Estimated Ratio Mask
Male Utter + cafeteria noise at SNR = 0 (dB)
Uttering: "The fan whirled its round blades softly"

|
|
|
|
|
|
|
|
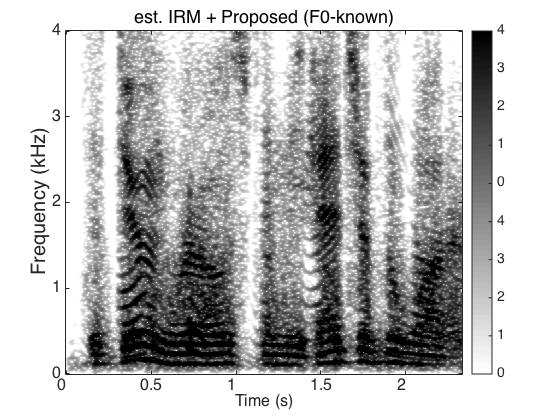
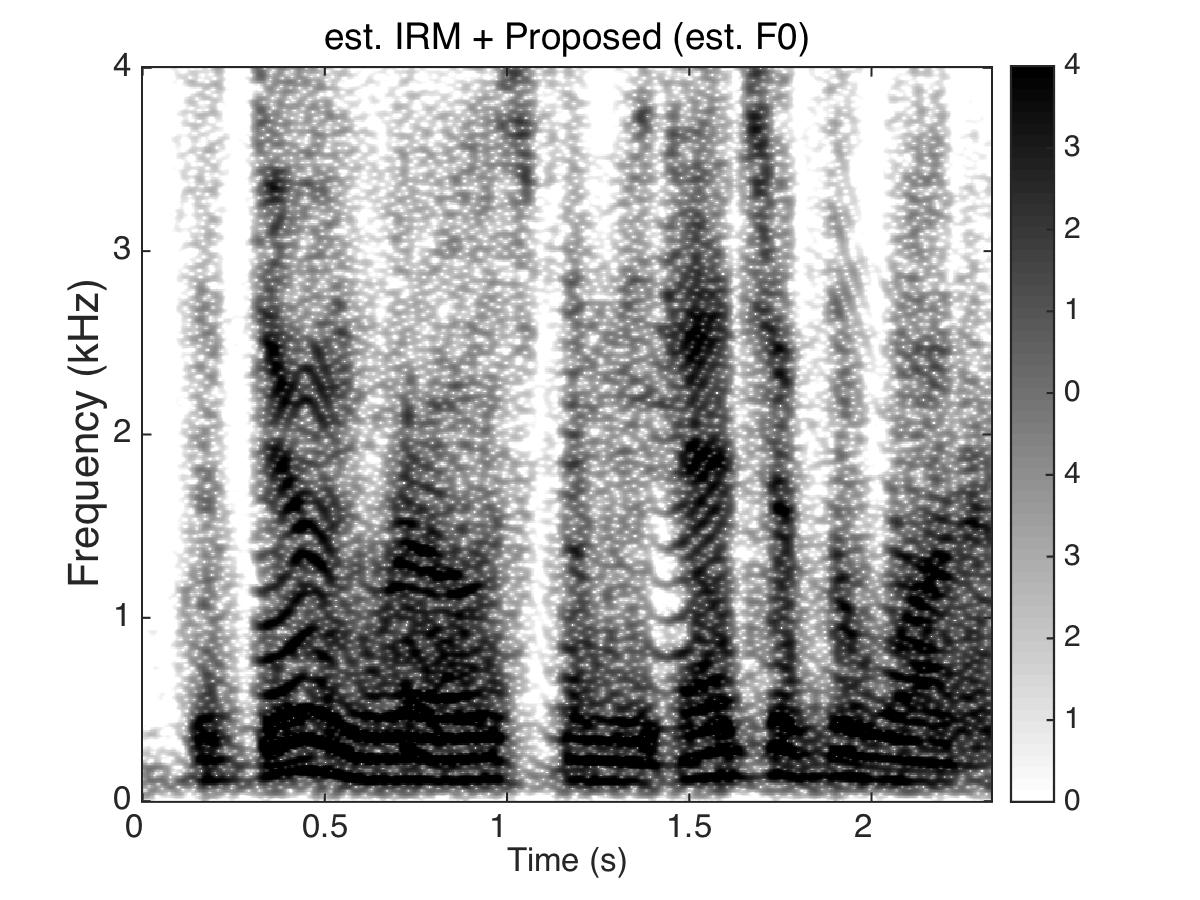
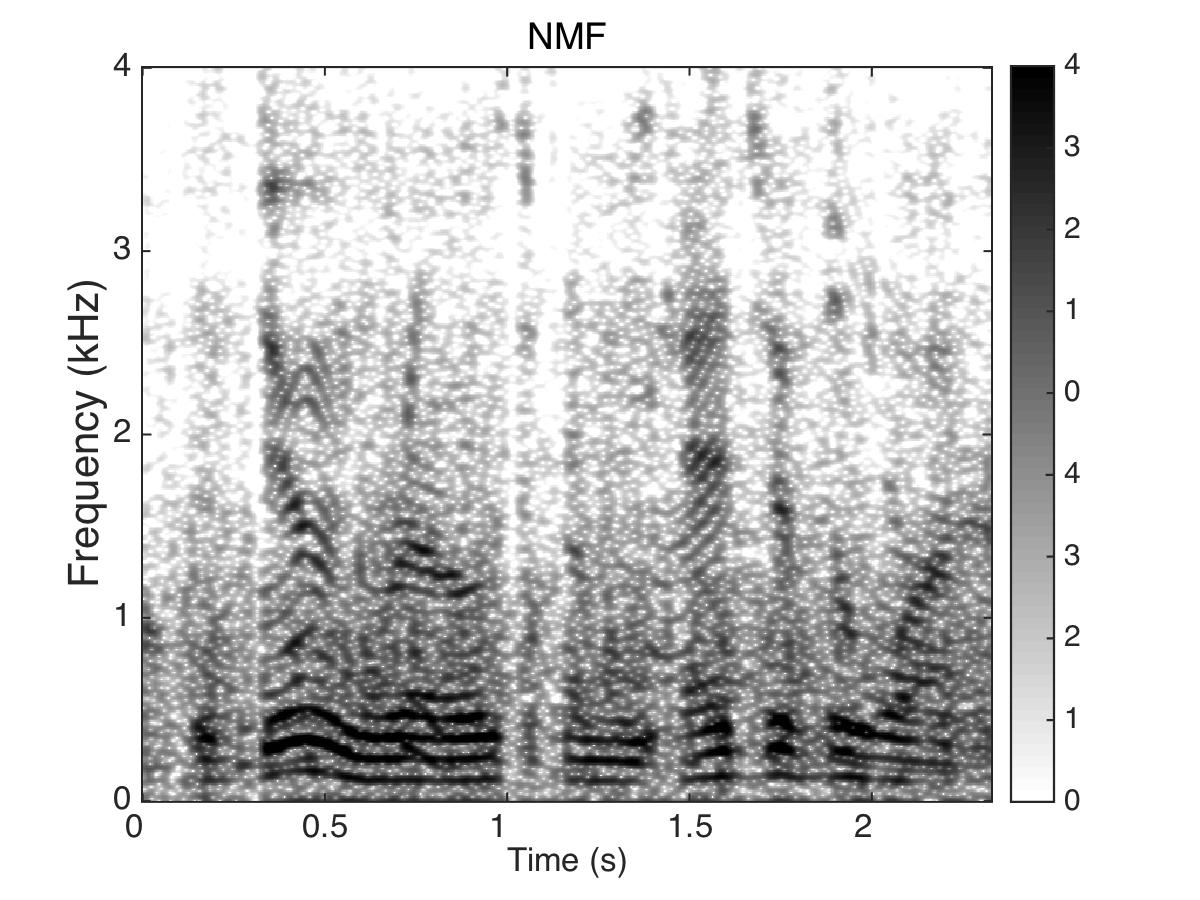
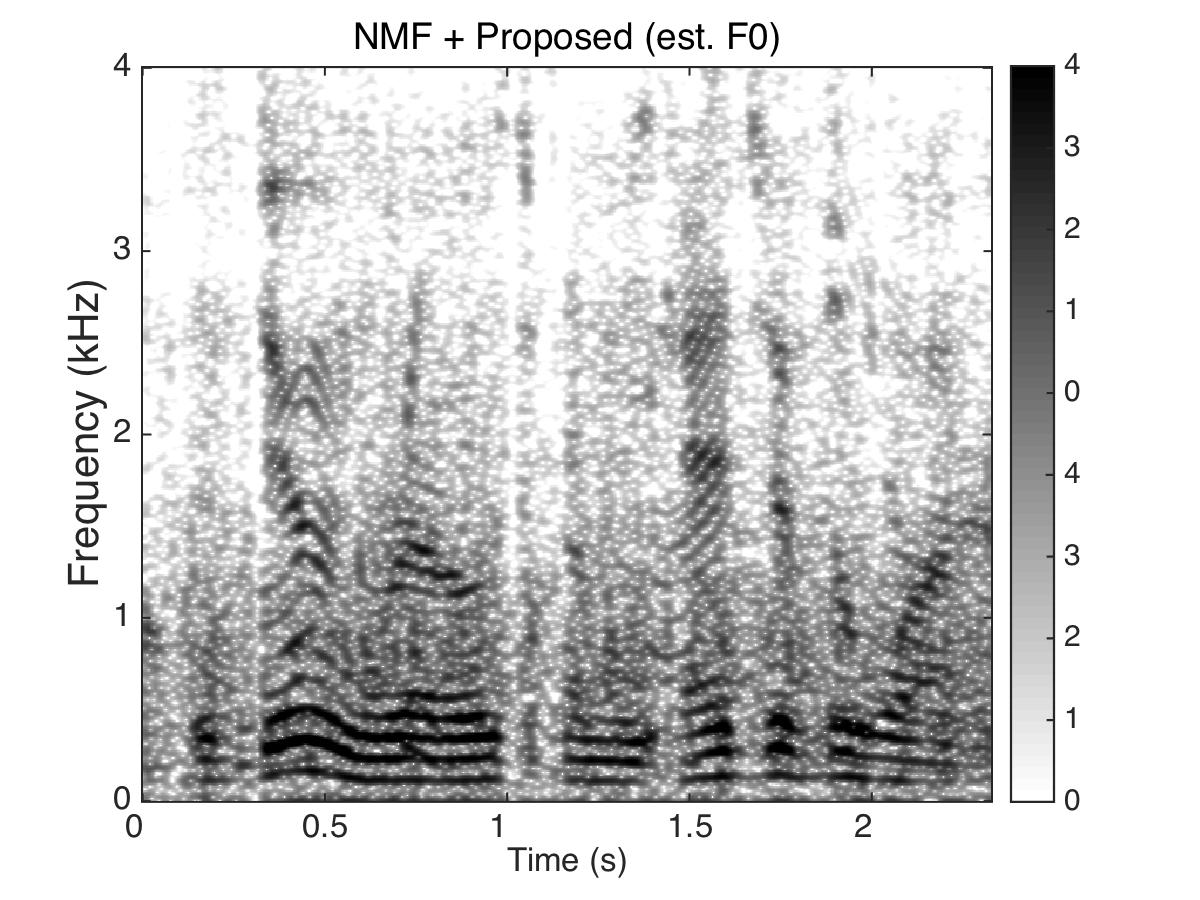
Experiment Two
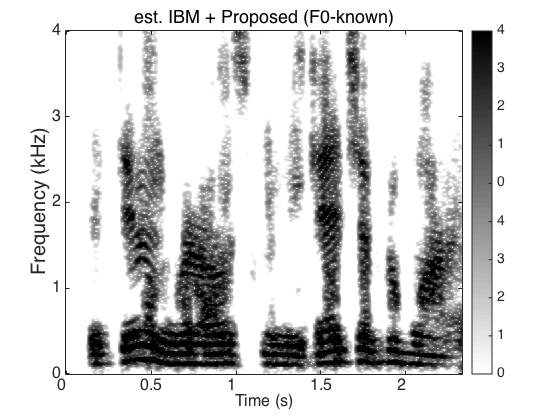
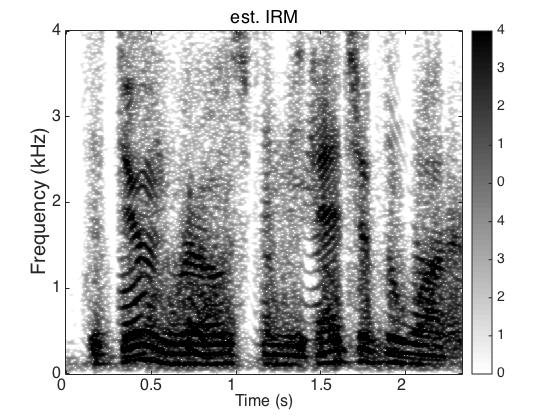
Target Speaker
Male Utter + Female Utter at SNR = 0 (dB) + Speech Shaped Noise (SSN)
Uttering: "The dune rose from the edge of the water"
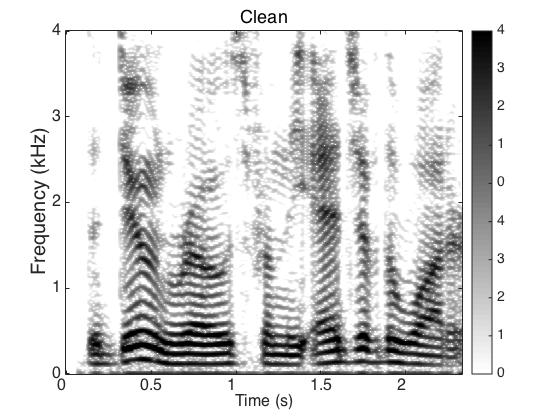
|
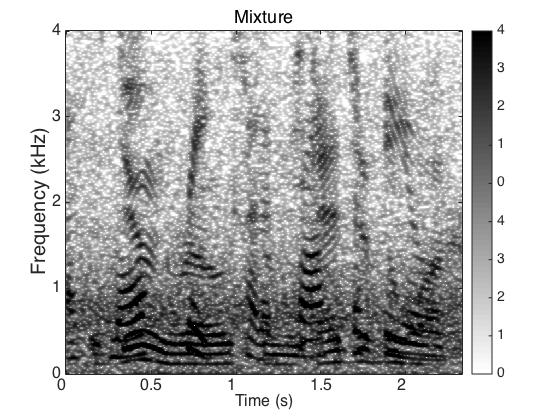
|
|

|
|
|
|
|

|
|
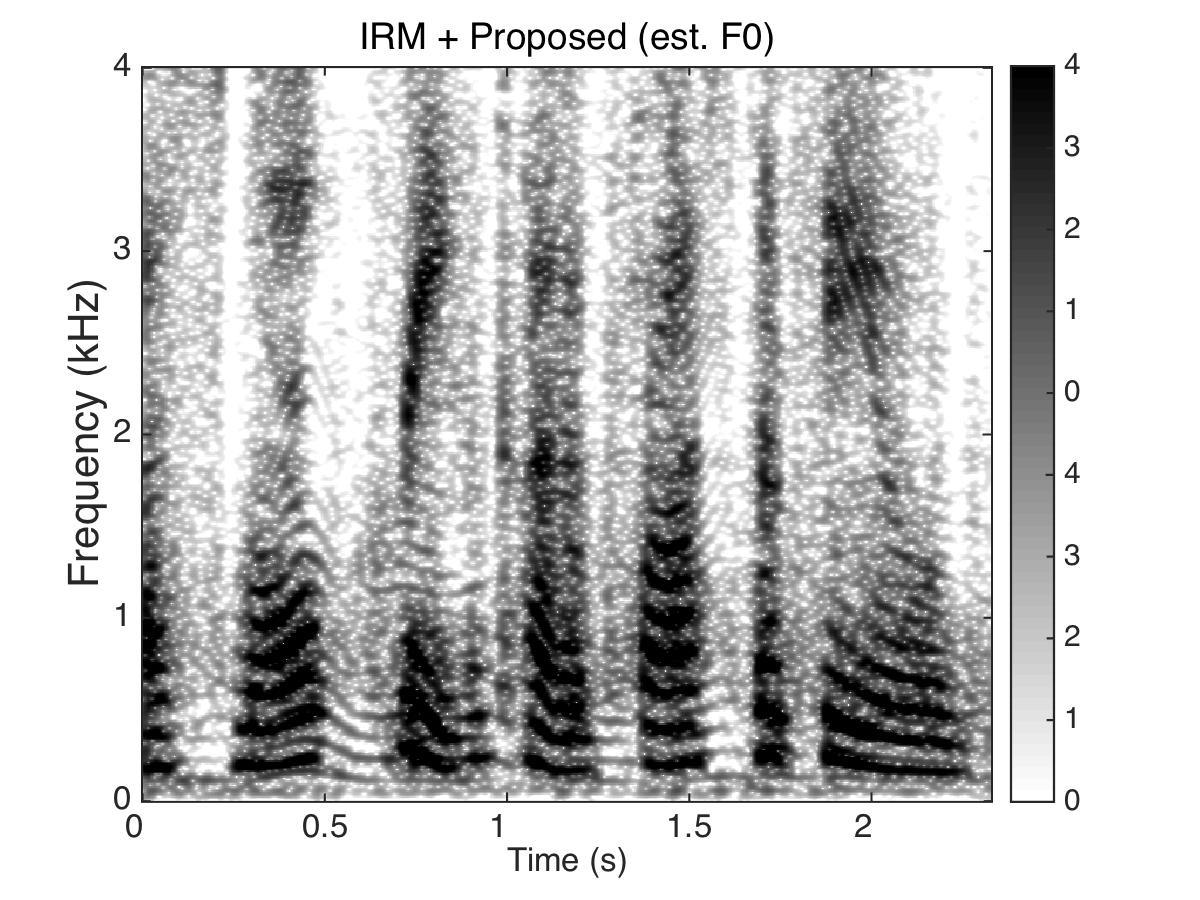
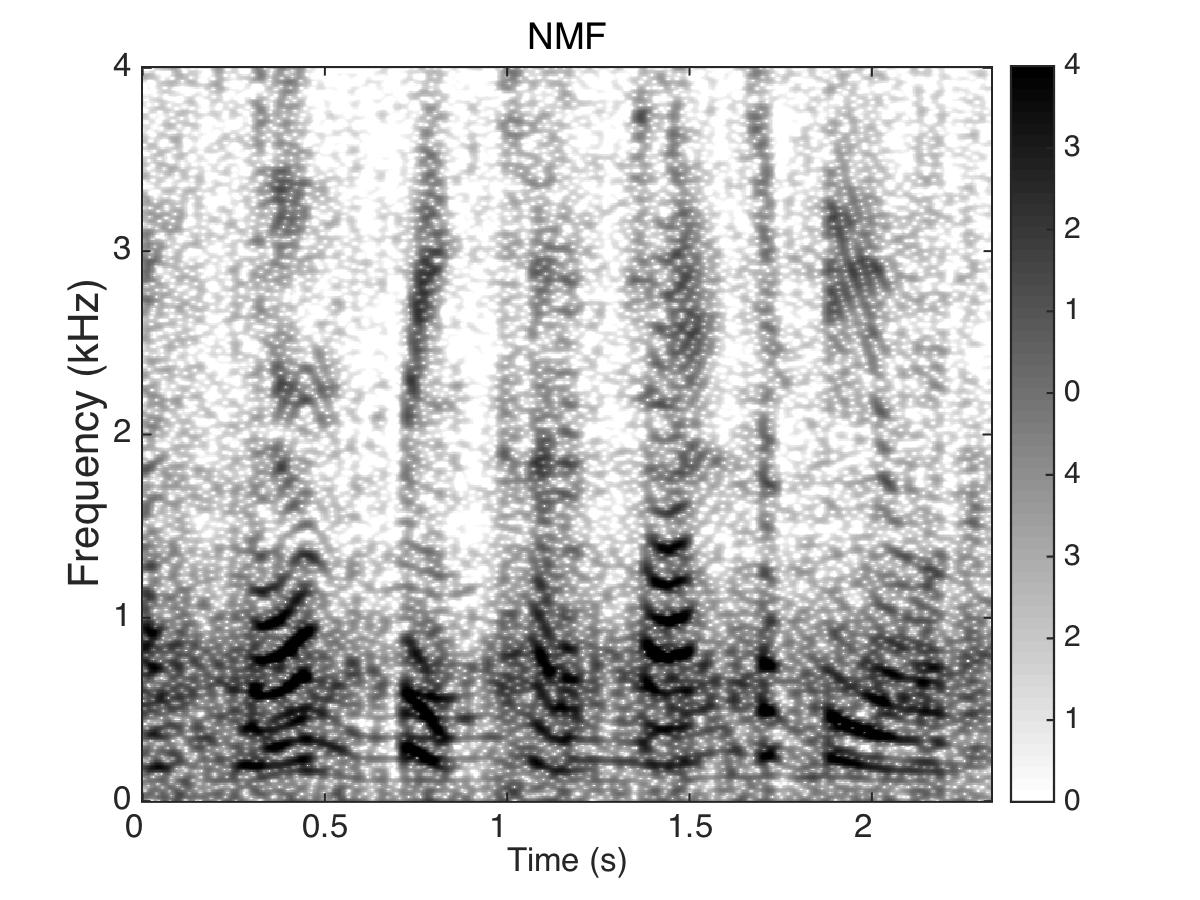
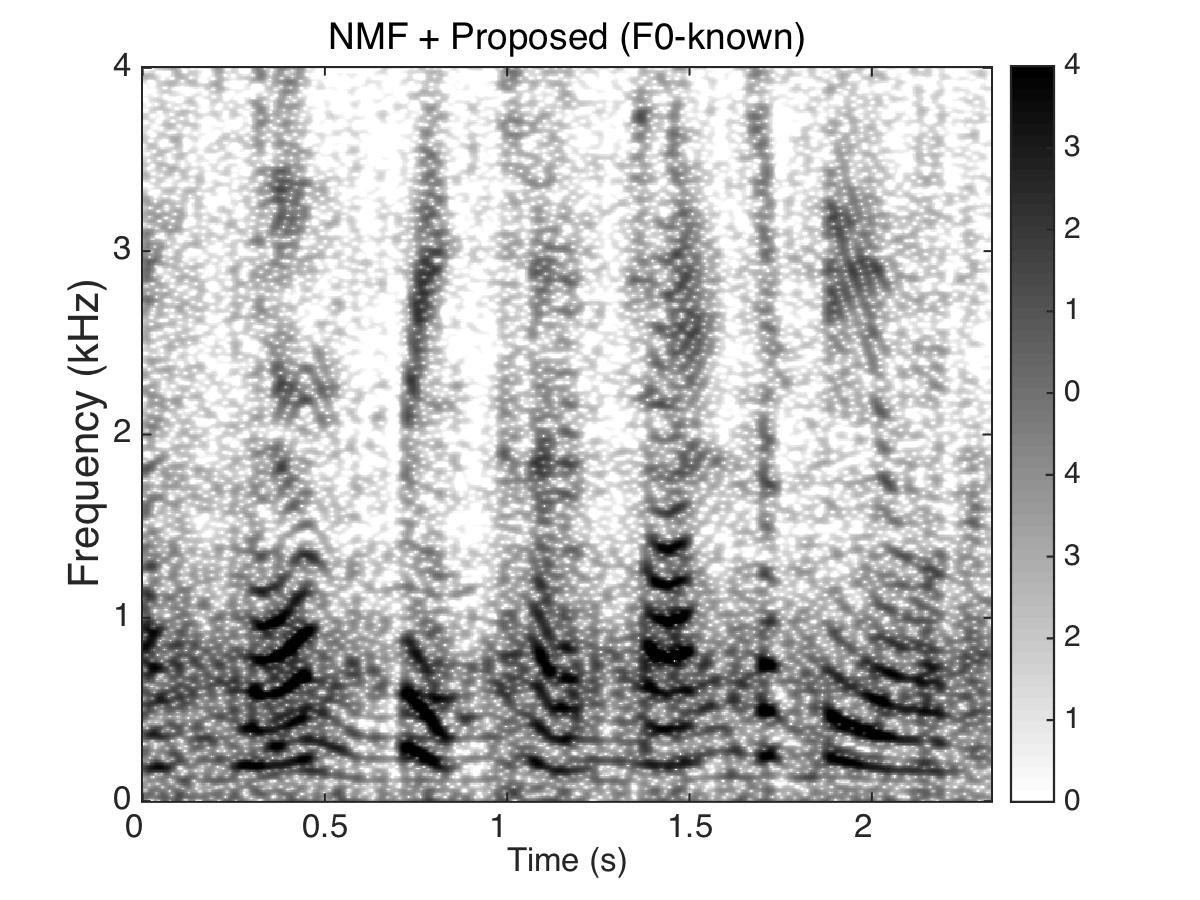
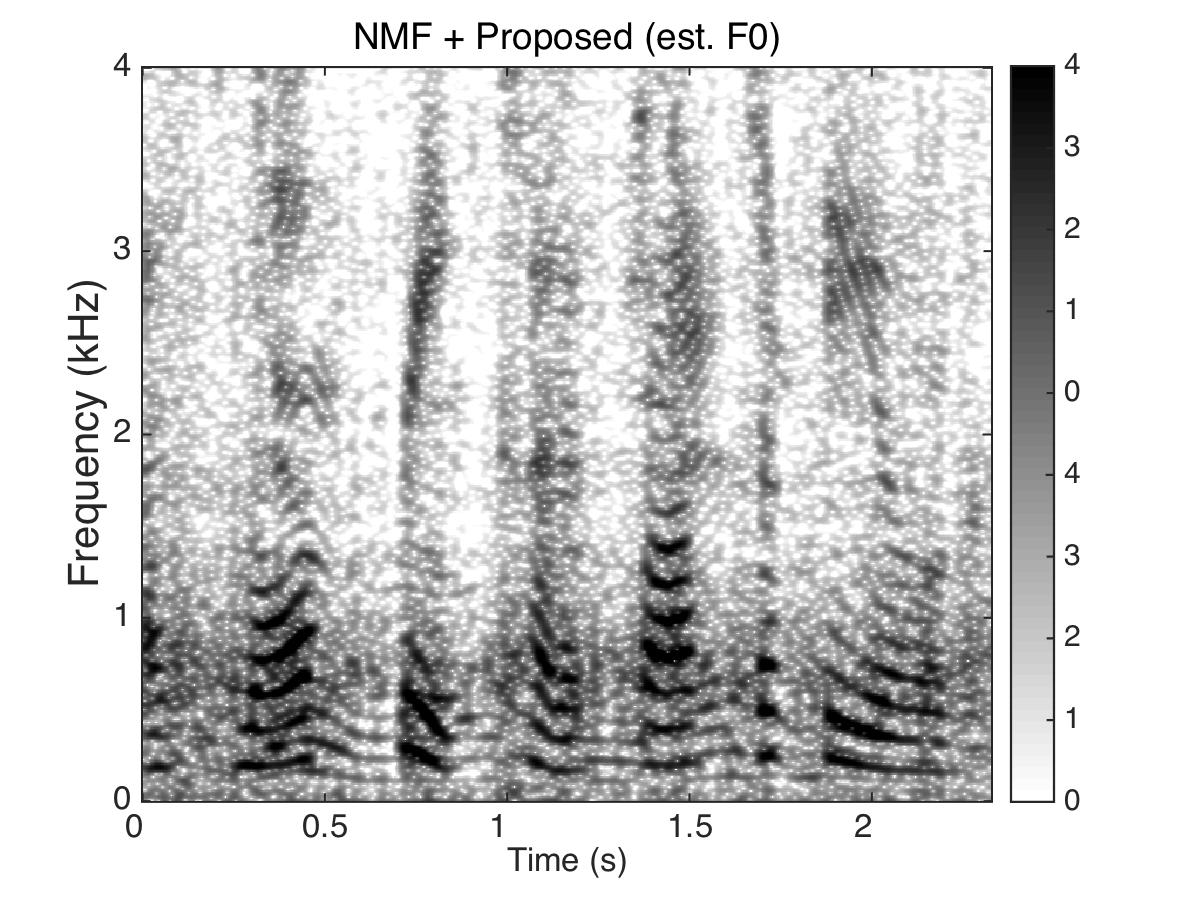
Experiment Two
Masking Speaker
Male Utter + Female Utter at SNR = 0 (dB) + Speech Shaped Noise (SSN)
Uttering: "A small creek cut across the field"

|
|
|
|
|
|
|
|
|
|