Source Separation
Followed by the first speech separation and recognition challenge in 2006, the more realistic scenario was released as SiSEC and CHiME in 2011 where additional realistic background
noise were added to GRID sentences recorded in a reverberant environment. In the following contributions, we investigated the trade-off between a speech enhancement and noise estimation and speaker-dependent source separation algorithm. We further extended the idea to binaural scenario by combining a GMM-based model-driven speech enhancement as a postfilter after the beamforming and noise suppression stages. For a recent overview on the phase-aware single-channel source separation we refer to
"Ch. 5 in the book" .
F. Mayer, D. S. Williamson, P. Mowlaee, D. Wang, "Impact of Phase Estimation on Single-Channel Speech Separation Based on Time-Frequency Masking" , Journal of Acoustic Society of America, vol. 141, no. 6, pp. 4668-4679, June 2017.
[pdf][ Audio].
T. Schrank, L. Pfeifenberger, M. Zöhrer, J. Stahl, P. Mowlaee and F. Pernkopf, "Deep beamforming and data augmentation for robust speech recognition: Results of the 4th CHiME Challenge " , in Proc. the 4th International Workshop on Speech Processing in Everyday Environments, San Fransisco, USA, September 2016.
F. Mayer, P. Mowlaee, "Improved Phase Reconstruction in Single-Channel Speech Separation" , in Proc. INTERSPEECH 2015, pp. 1795-1799, Dresden, Germany, September 2015.
[Matlab].
P. Mowlaee, C. Nachbar, "Speaker Dependent Speech Enhancement Using Sinusoidal Model" , The International Workshop on Acoustic Signal Enhancement (IWAENC 2014), pp. 81-85, 2014.
P. Mowlaee, R. Saeidi, "Target Speaker separation in a Multisource Environment Using Speaker-dependent Postfilter and Noise Estimation" , IEEE Int. Conf. Acoustics, Speech, Signal Processing, May. 2013, Vancouver, Canada [Matlab].
P. Mowlaee, R. Saeidi, R. Martin, "Model-driven speech enhancement for multisource reverberant environment (Signal Separation Evaluation Campaign (SiSEC) 2011)" , Proceedings of the 10th International Conference on Latent Variable Analysis and Source Separation, LVA/ICA, 454-461, 2012. [Matlab].
P. Mowlaee, J. A. Morales-Cordovilla, F. Pernkopf, H. Passentheiner, M. Hagmuller, and G. Kubin, "The 2nd 'CHiME'
Speech Separation and Recognition Challenge: Approaches on Single-channel Speech Separation and Model-driven
Speech Enhancement", in Proceeding of the 2nd CHiME Speech Separation and Recognition Challenge," IEEE Int. Conf. Acoustics, Speech, Signal Processing, May. 2013, Vancouver, Canada.
[Audio]
P. Mowlaee, M. Christensen, and S. Jensen, "New results on single-channel speech separation using sinusoidal modeling" , IEEE Trans. Audio, Speech, and Language Process. vol. 19, no. 5, pp. 1265 – 1277, 2011.
M. G. Christensen, P. Mowlaee, "A new metric for VQ-based speech enhancement and separation" , IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 4764 -4767, may, 2011.
P. Mowlaee, R. Saeidi, Z.-H, Tan, M. G. Christensen, T. Kinnunen, P. Fränti, S. H. Jensen, "A Joint Approach for single-channel Speaker Identification and Speech Separation" , IEEE Transactions on Audio, Speech and Language Processing, vol. 20, no. 9, pp. 2586-2601, 2012.
P. Mowlaee, R. Saeidi, Z.-H, Tan, M. G. Christensen, P. Fränti, S. H. Jensen, "Joint single-channel speech separation and speaker identification" , in Proc. 35th IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Dallas, USA, pp. 4430-4433, March 2010.
P. Mowlaee, "New Stategies for Single-Channel Speech Separation" , Ph.D. thesis, Institut for Elektroniske Systemer, Aalborg Universitet, Aalborg, Denmark, 2010.
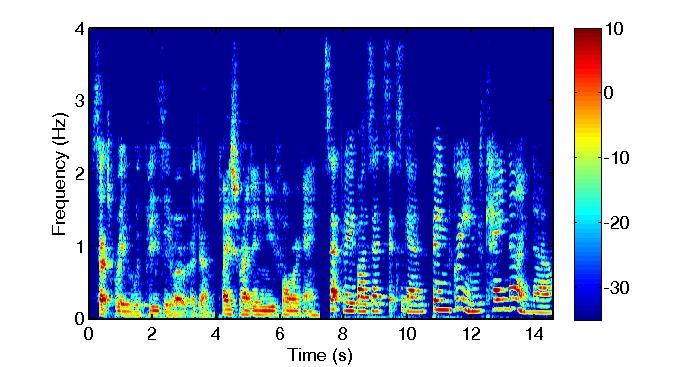
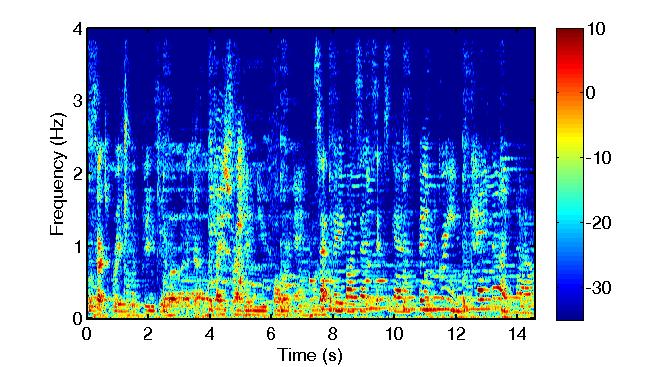
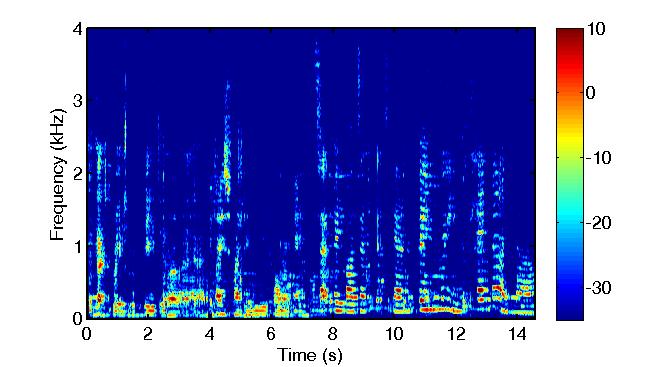
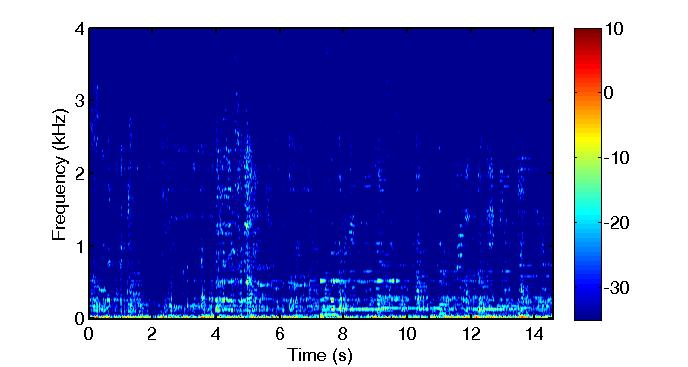
Multisource reverberant environment at SNR = 3 (dB):
Clean Speech
Your browser does not support the audio element.
Noisy Speech
Your browser does not support the audio element.
Enhanced Target Speech
Your browser does not support the audio element.
Separated Noise
Your browser does not support the audio element.